概要
MpscGrowableArrayQueue是JCTools里的一个工具,是对于特定场景化的定制,即MPSC(Multi-Producer & Single-Consumer),在这种场景下,相对于BlockingQueue,能够满足高性能的需要。
背景
JCTools是一款对jdk并发数据结构进行增强的并发工具,主要提供了map以及queue的增强数据结构。
Mpsc**ArrayQueue是由JCTools提供的一个多生产者单个消费者的数组队列。多个生产者同时并发的访问队列是线程安全的,但是同一时刻只允许一个消费者访问队列,这是需要程序控制的,因为MpscQueue的用途即为多个生成者可同时访问队列,但只有一个消费者会访问队列的情况。如果是其他情况你可以使用JCTools提供的其他队列。
应用场景
上面说了MpscGrowableArrayQueue是用于特定化场景,即MPSC。其实这种场景我们平时也会看到很多,在各种框架、工具中也有它的身影。
Netty
原来Netty还是自己写的MpscLinkedQueueNode,后来新版本就换成使用JCTools的并发队列了。
Netty的线程模型决定了taskQueue可以用多个生产者线程同时提交任务,但只会有EventLoop所在线程来消费taskQueue队列中的任务。这样JCTools提供的MpscQueue完全符合Netty线程模式的使用场景。而LinkedBlockingQueue会在生产者线程操作队列时以及消费者线程操作队列时都对队列加锁以保证线程安全性。虽然,在Netty的线程模型中程序会控制访问taskQueue的始终都会是EventLoop所在线程,这时会使用偏向锁来降低线程获得锁的代价。
Caffeine
像我的一篇文章说的(Caffeine高性能设计剖析),如果对Caffeine设置了expireAfterWrite或refreshAfterWrite,那么每次写操作都会把afterWrite的task放在一个MpscGrowableArrayQueue里,之后再异步处理这些task。一般写操作有可能并发进行,有多个生产者, 但是只用一个线程来处理,来降低复杂度,这里的场景就很适合mpsc了。
使用
MpscGrowableArrayQueue的使用跟其他queue类似,提供offer, poll, peek等常规方法,但由于特定化的场景,由于设计上的原因,做了一点限制,相当于牺牲了一些功能,不支持这三个方法:remove(Object o),removeAll(Collection),retainAll(Collection)。
原理分析
BlockingQueue对于每次的读写都会使用锁Lock来阻塞操作,这样在高并发下会产生性能问题,影响程序的吞吐量,那么对于这种情况的优化,很自然就会想到要把锁去掉,采用Lock-free的设计,这是生产端的原理;对于消费端,干脆只限制只有一个线程来使用(没有强制限制),那么就不存在并发问题了。
下面我们来看看MpscGrowableArrayQueue的具体实现(源码基于jctools的3.0.0版本
):
###基本属性
先看看MpscGrowableArrayQueue的继承关系
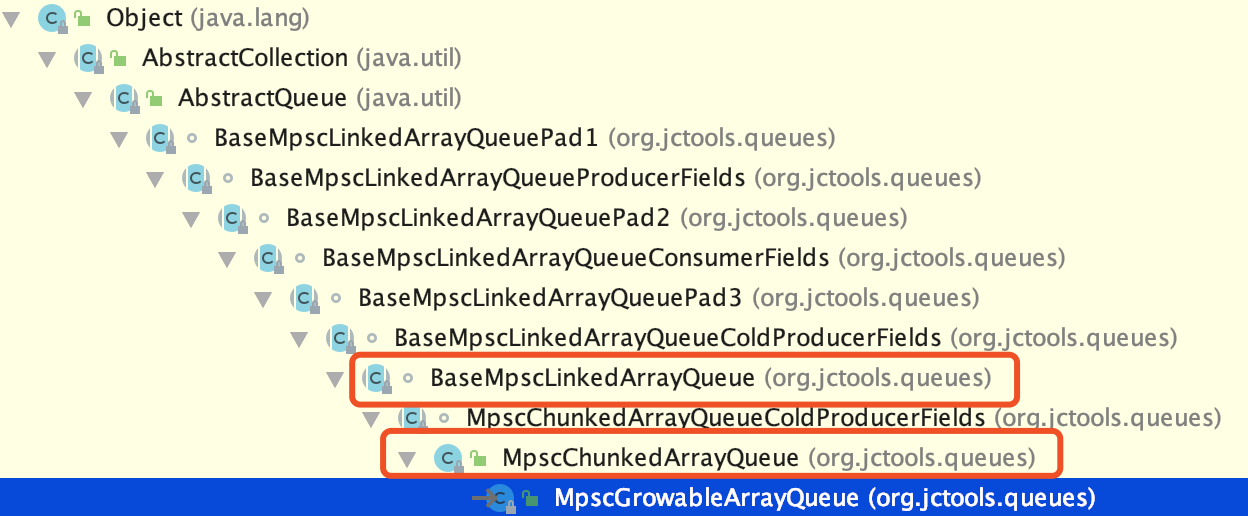
重点看红框框着的,其他都是用于padding的。MpscGrowableArrayQueue和MpscChunkedArrayQueue的功能差不多,他们都继承于BaseMpscLinkedArrayQueue类。
相对于其他Mpsc**Queue类,MpscChunkedArrayQueue根据名字可以看出它是基于数组实现,跟准确的说是数组链表。这点可从它的父类BaseMpscLinkedArrayQueue看出。它融合了链表和数组,既可以动态变化长度,同时不会像链表频繁分配Node。并且吞吐量优于传统的链表。
BaseMpscLinkedArrayQueue实现了绝大部分的核心功能,下面讲到的源码都在这个类里面。
看看官方对MpscGrowableArrayQueue的定义:
1 | /** |
它是一个可自动扩展容量的array,扩展时它不会像hashmap那样把旧数组的元素复制到新的数组,而是用一个link来连接到新的数组。
BaseMpscLinkedArrayQueue的主要几个属性,这几个属性比较分散(由于用了很多的padding类来做继承),我把他们集中起来:
1 | //生产者的最大下标 |
初始化
1 | /** |
可以看出初始化时初始化了init size的数组,以及mask,limit等。
注意,producer和consumer的index初始值都为0,这里没写。
offer
一个queue需要往里面加入元素,offer操作是其最基本的功能。
1 | public boolean offer(final E e) { |
offerSlowPath方法:
1 |
|
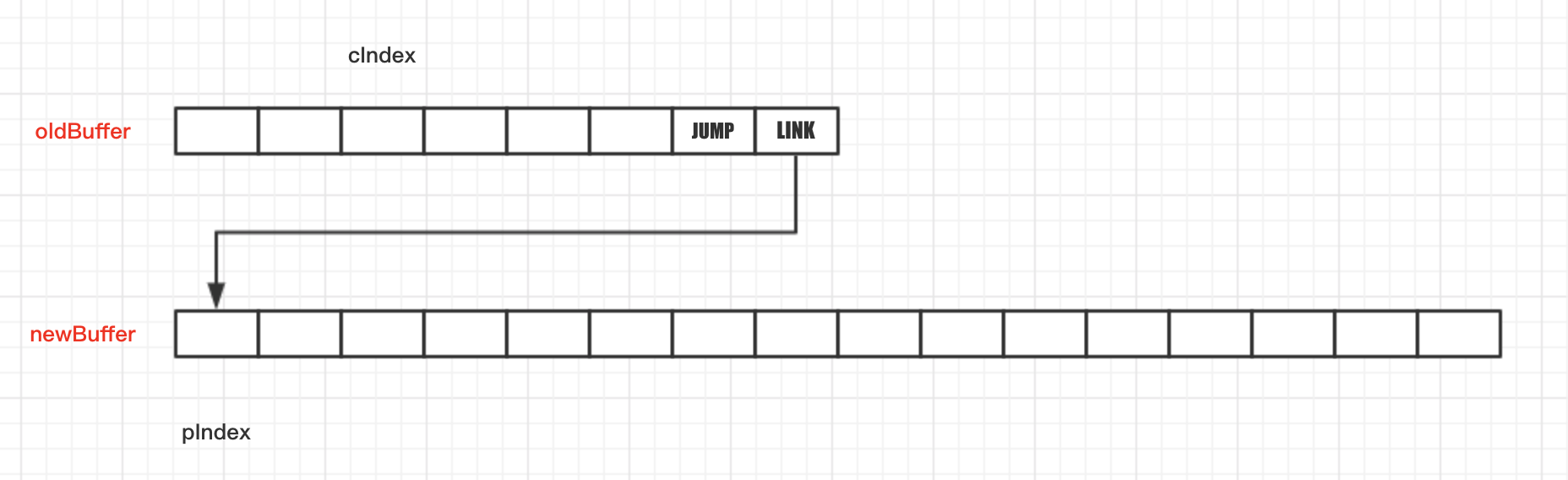
resize方法:
1 | private void resize(long oldMask, E[] oldBuffer, long pIndex, E e, Supplier<E> s) |
poll
poll方法:
注意这个方法会有并发问题,所以MPSC的使用要求是一次只用一个线程来poll。
1 | public E poll() |
结构图
总结
在多生产者单消费者的场景下,使用MpscGrowableArrayQueue可以满足高性能的队列读写要求。
MpscGrowableArrayQueue不再使用Lock来阻塞操作,而是使用CAS来操作,包括使用putOrderedObject来进行快速set、使用arrayBaseOffset和arrayIndexScale来计算数组的偏移量等等;
还有padding来解决伪共享问题。