概要
Caffeine是一个高性能,高命中率,低内存占用,near optimal 的本地缓存,简单来说它是Guava Cache的优化加强版,有些文章把Caffeine称为“新一代的缓存”、“现代缓存之王”。本文将重点讲解Caffeine的高性能设计,以及对应部分的源码分析。
与Guava Cache比较
如果你对Guava Cache还不理解的话,可以点击这里来看一下我之前写过关于Guava Cache的文章。
大家都知道,Spring5即将放弃掉Guava Cache作为缓存机制,而改用Caffeine作为新的本地Cache的组件,这对于Caffeine来说是一个很大的肯定。为什么Spring会这样做呢?其实在Caffeine的Benchmarks里给出了好靓仔的数据,对读和写的场景,还有跟其他几个缓存工具进行了比较,Caffeine的性能都表现很突出。
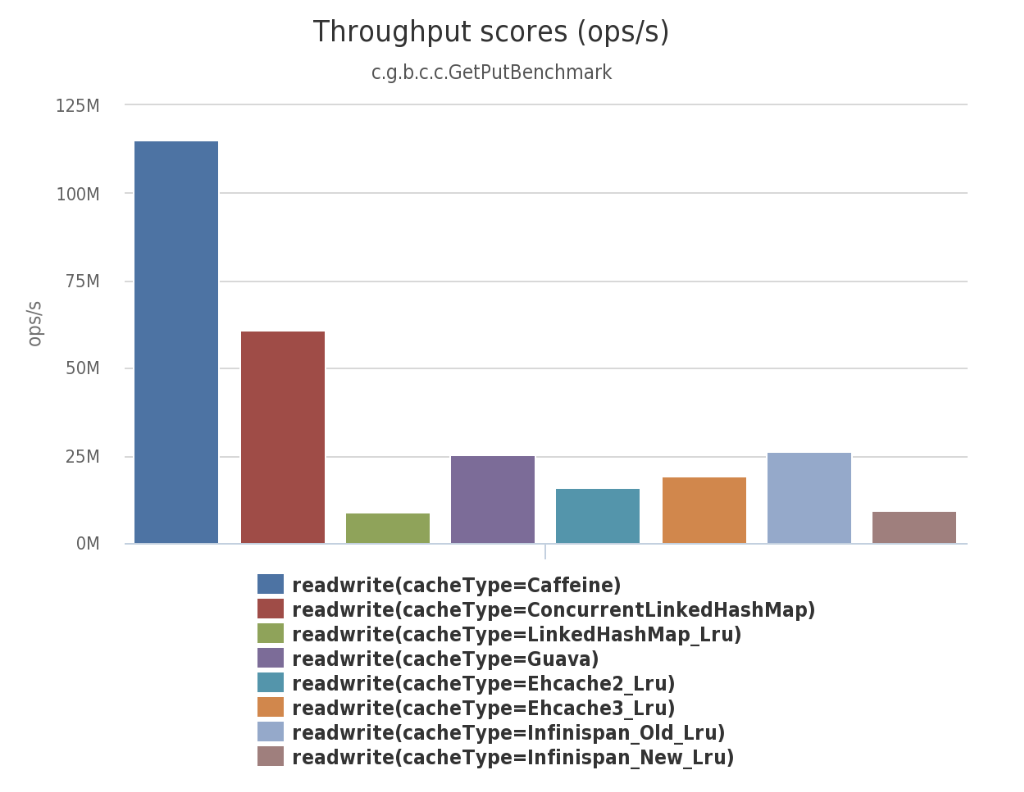
使用Caffeine
Caffeine为了方便大家使用以及从Guava Cache切换过来(很有针对性啊~),借鉴了Guava Cache大部分的概念(诸如核心概念Cache、LoadingCache、CacheLoader、CacheBuilder等等),对于Caffeine的理解只要把它当作Guava Cache就可以了。
使用上,大家只要把Caffeine的包引进来,然后换一下cache的实现类,基本应该就没问题了。这对与已经使用过Guava Cache的同学来说没有任何难度,甚至还有一点熟悉的味道,如果你之前没有使用过Guava Cache,可以查看Caffeine的官方API说明文档,其中Population,Eviction,Removal,Refresh,Statistics,Cleanup,Policy等等这些特性都是跟Guava Cache基本一样的。
下面给出一个例子说明怎样创建一个Cache:
1 | private static LoadingCache<String, String> cache = Caffeine.newBuilder() |
更多从Guava Cache迁移过来的使用说明,请看这里
Caffeine的高性能设计
判断一个缓存的好坏最核心的指标就是命中率,影响缓存命中率有很多因素,包括业务场景、淘汰策略、清理策略、缓存容量等等。如果作为本地缓存, 它的性能的情况,资源的占用也都是一个很重要的指标。下面
我们来看看Caffeine在这几个方面是怎么着手的,如何做优化的。
(注:本文不会分析Caffeine全部源码,只会对核心设计的实现进行分析,但我建议读者把Caffeine的源码都涉猎一下,有个overview才能更好理解本文。如果你看过Guava Cache的源码也行,代码的数据结构和处理逻辑很类似的。
源码基于:caffeine-2.8.0.jar)
W-TinyLFU整体设计
上面说到淘汰策略是影响缓存命中率的因素之一,一般比较简单的缓存就会直接用到LFU(Least Frequently Used,即最不经常使用)或者LRU(Least Recently Used,即最近最少使用),而Caffeine就是使用了W-TinyLFU算法。
W-TinyLFU看名字就能大概猜出来,它是LFU的变种,也是一种缓存淘汰算法。那为什么要使用W-TinyLFU呢?
LRU和LFU的缺点
LRU实现简单,在一般情况下能够表现出很好的命中率,是一个“性价比”很高的算法,平时也很常用。虽然LRU对突发性的稀疏流量(sparse bursts)表现很好,但同时也会产生缓存污染,举例来说,如果偶然性的要对全量数据进行遍历,那么“历史访问记录”就会被刷走,造成污染。
如果数据的分布在一段时间内是固定的话,那么LFU可以达到最高的命中率。但是LFU有两个缺点,第一,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;第二,对突发性的稀疏流量无力,因为前期经常访问的记录已经占用了缓存,偶然的流量不太可能会被保留下来,而且过去的一些大量被访问的记录在将来也不一定会使用上,这样就一直把“坑”占着了。
无论LRU还是LFU都有其各自的缺点,不过,现在已经有很多针对其缺点而改良、优化出来的变种算法。
TinyLFU
TinyLFU就是其中一个优化算法,它是专门为了解决LFU上述提到的两个问题而被设计出来的。
解决第一个问题是采用了Count–Min Sketch算法。
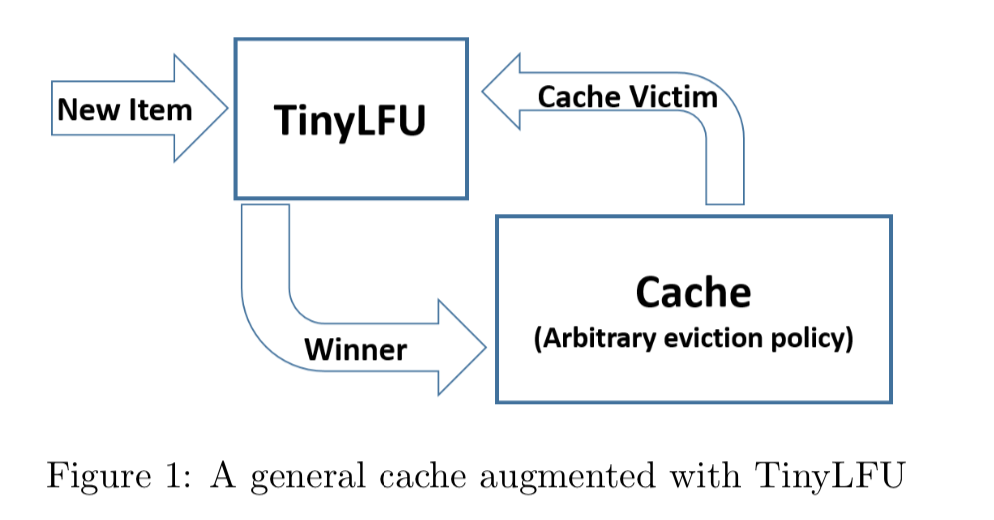
解决第二个问题是让记录尽量保持相对的“新鲜”(Freshness Mechanism),并且当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除。
下图是TinyLFU设计图(来自官方)
统计频率Count–Min Sketch算法
如何对一个key进行统计,但又可以节省空间呢?(不是简单的使用HashMap,这太消耗内存了),注意哦,不需要精确的统计,只需要一个近似值就可以了,怎么样,这样场景是不是很熟悉,如果你是老司机,或许已经联想到布隆过滤器(Bloom Filter)的应用了。
没错,将要介绍的Count–Min Sketch的原理跟Bloom Filter一样,只不过Bloom Filter只有0和1的值,那么你可以把Count–Min Sketch看作是“数值”版的Bloom Filter。
更多关于Count–Min Sketch的介绍请自行搜索。
在TinyLFU中,近似频率的统计如下图所示:
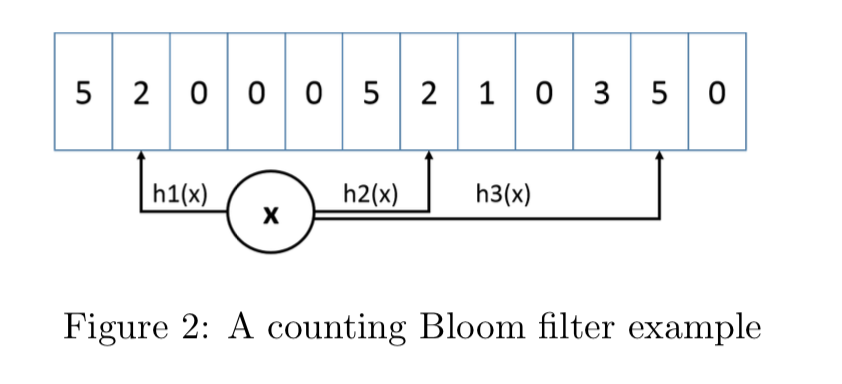
对一个key进行多次hash函数后,index到多个数组位置后进行累加,查询时取多个值中的最小值即可。
Caffeine对这个算法的实现在FrequencySketch类。但Caffeine对此有进一步的优化,例如Count–Min Sketch使用了二维数组,Caffeine只是用了一个一维的数组;再者,如果是数值类型的话,这个数需要用int或long来存储,但是Caffeine认为缓存的访问频率不需要用到那么大,只需要15就足够,一般认为达到15次的频率算是很高的了,而且Caffeine还有另外一个机制来使得这个频率进行衰退减半(下面就会讲到)。如果最大是15的话,那么只需要4个bit就可以满足了,一个long有64bit,可以存储16个这样的统计数,Caffeine就是这样的设计,使得存储效率提高了16倍。
Caffeine对缓存的读写(afterRead和afterWrite方法)都会调用onAccesss方法,而onAccess方法里有一句:
1 | frequencySketch().increment(key); |
这句就是追加记录的频率,下面我们看看具体实现
1 |
|
知道了追加方法,那么读取方法frequency就很容易理解了。
1 |
|
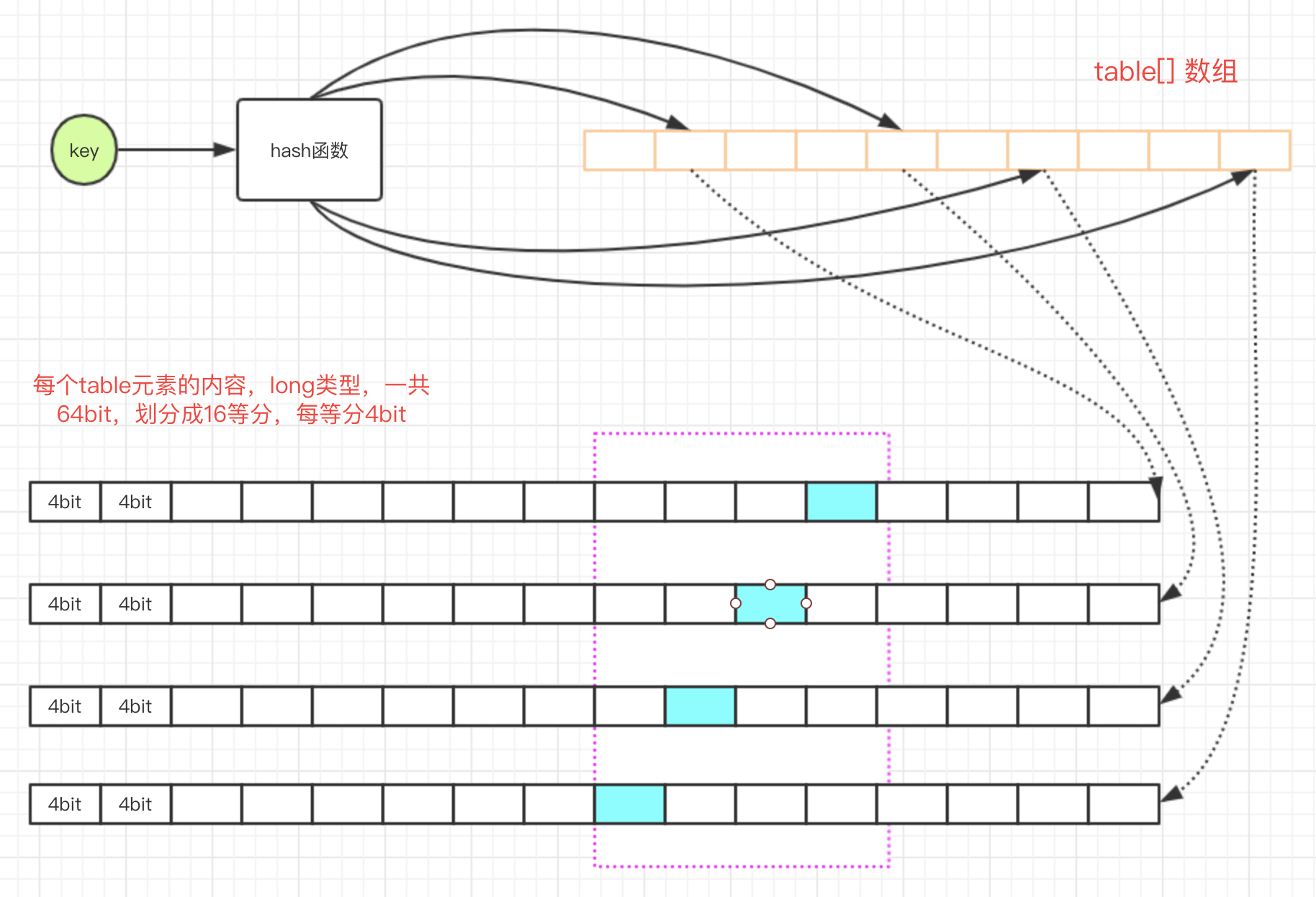
通过代码和注释或者读者可能难以理解,下图是我画出来帮助大家理解的结构图。
注意紫色虚线框,其中蓝色小格就是需要计算的位置:
保新机制
为了让缓存保持“新鲜”,剔除掉过往频率很高但之后不经常的缓存,Caffeine有一个Freshness Mechanism。做法很简答,就是当整体的统计计数(当前所有记录的频率统计之和,这个数值内部维护)达到某一个值时,那么所有记录的频率统计除以2。
从上面的代码
1 | //size变量就是所有记录的频率统计之,即每个记录加1,这个size都会加1 |
看到reset方法就是做这个事情
1 |
|
关于这个reset方法,为什么是除以2,而不是其他,及其正确性,在最下面的参考资料的TinyLFU论文中3.3章节给出了数学证明,大家有兴趣可以看看。
增加一个Window?
Caffeine通过测试发现TinyLFU在面对突发性的稀疏流量(sparse bursts)时表现很差,因为新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降。
于是Caffeine设计出一种新的policy,即Window Tiny LFU(W-TinyLFU),并通过实验和实践发现W-TinyLFU比TinyLFU表现的更好。
W-TinyLFU的设计如下所示(两图等价):
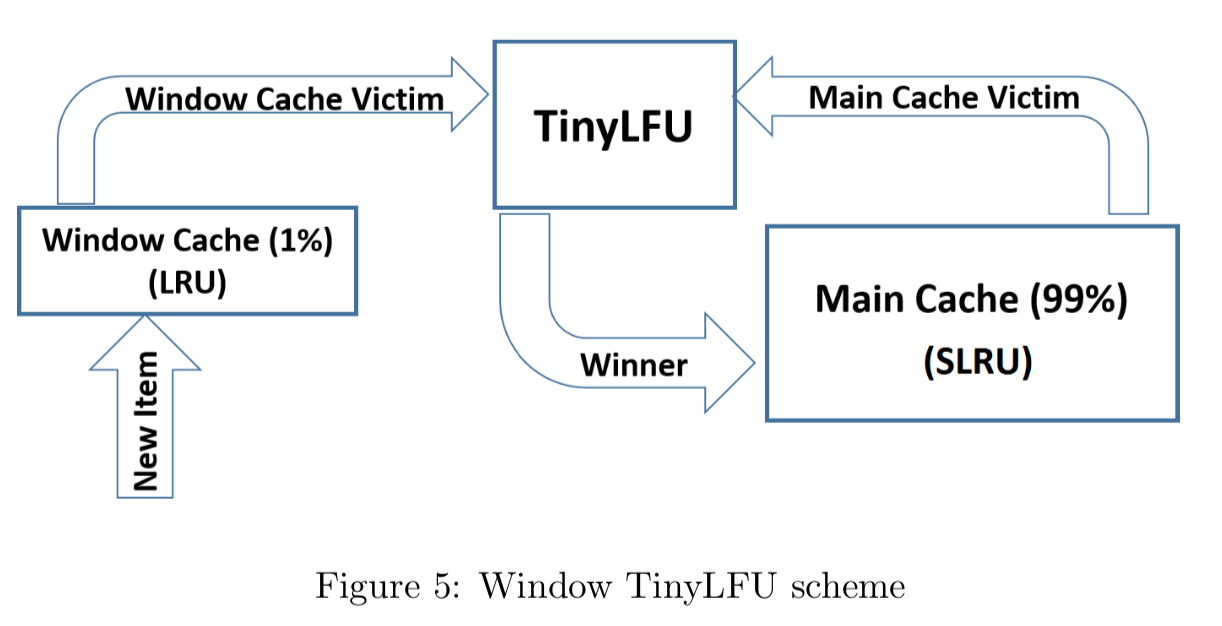
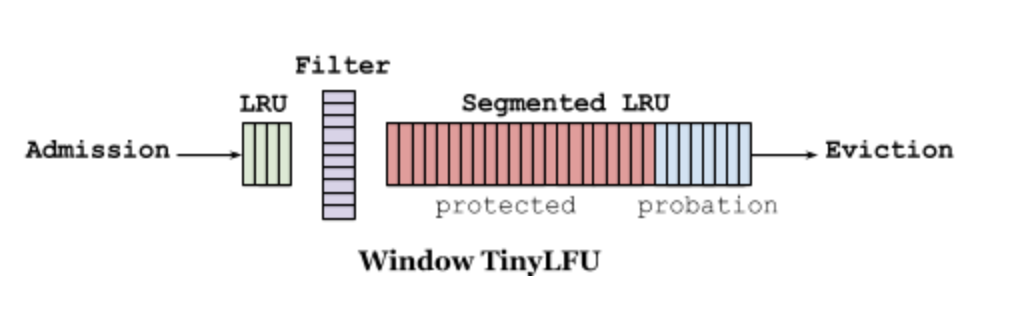
它主要包括两个缓存模块,主缓存是SLRU(Segmented LRU,即分段LRU),SLRU包括一个名为protected和一个名为probation的缓存区。通过增加一个缓存区(即Window Cache),当有新的记录插入时,会先在window区呆一下,就可以避免上述说的sparse bursts问题。
淘汰策略(eviction policy)
当window区满了,就会根据LRU把candidate(即淘汰出来的元素)放到probation区,如果probation区也满了,就把candidate和probation将要淘汰的元素victim,两个进行“PK”,胜者留在probation,输者就要被淘汰了。
而且经过实验发现当window区配置为总容量的1%,剩余的99%当中的80%分给protected区,20%分给probation区时,这时整体性能和命中率表现得最好,所以Caffeine默认的比例设置就是这个。
不过这个比例Caffeine会在运行时根据统计数据(statistics)去动态调整,如果你的应用程序的缓存随着时间变化比较快的话,那么增加window区的比例可以提高命中率,相反缓存都是比较固定不变的话,增加Main Cache区(protected区 +probation区)的比例会有较好的效果。
下面我们看看上面说到的淘汰策略是怎么实现的:
一般缓存对读写操作后都有后续的一系列“维护”操作,Caffeine也不例外,这些操作都在maintenance方法,我们将要说到的淘汰策略也在里面。
这方法比较重要,下面也会提到,所以这里只先说跟“淘汰策略”有关的evictEntries和climb。
1 | /** |
先说一下Caffeine对上面说到的W-TinyLFU策略的实现用到的数据结构:
1 | //最大的个数限制 |
以及默认比例设置(意思看注释)
1 | /** The initial percent of the maximum weighted capacity dedicated to the main space. */ |
重点来了,evictEntries和climb方法:
1 | /** Evicts entries if the cache exceeds the maximum. */ |
evictFromMain方法:
1 | /** |
climb方法主要是用来调整window size的,使得Caffeine可以适应你的应用类型(如OLAP或OLTP)表现出最佳的命中率。
下图是官方测试的数据:
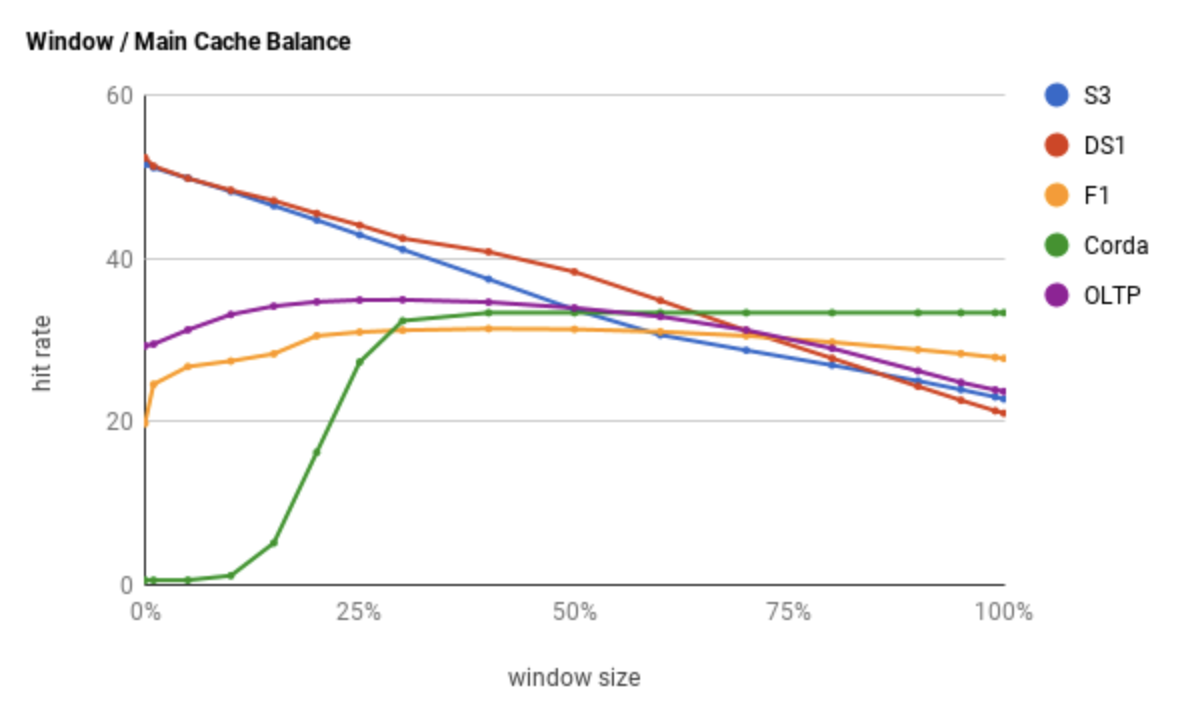
我们看看window size的调整是怎么实现的。
调整时用到的默认比例数据:
1 | //与上次命中率之差的阈值 |
1 | /** Adapts the eviction policy to towards the optimal recency / frequency configuration. */ |
下面分别展开每个方法来解释:
1 | /** Calculates the amount to adapt the window by and sets {@link #adjustment()} accordingly. */ |
以上,是Caffeine的W-TinyLFU策略的设计原理及代码实现解析。
异步的高性能读写
一般的缓存每次对数据处理完之后(读的话,已经存在则直接返回,不存在则load数据,保存,再返回;写的话,则直接插入或更新),但是因为要维护一些淘汰策略,则需要一些额外的操作,诸如:
- 计算和比较数据的是否过期
- 统计频率(像LFU或其变种)
- 维护read queue和write queue
- 淘汰符合条件的数据
- 等等。。。
这种数据的读写伴随着缓存状态的变更,Guava Cache的做法是把这些操作和读写操作放在一起,在一个同步加锁的操作中完成,虽然Guava Cache巧妙地利用了JDK的ConcurrentHashMap(分段锁或者无锁CAS)来降低锁的密度,达到提高并发度的目的。但是,对于一些热点数据,这种做法还是避免不了频繁的锁竞争。Caffeine借鉴了数据库系统的WAL(Write-Ahead Logging)思想,即先写日志再执行操作,这种思想同样适合缓存的,执行读写操作时,先把操作记录在缓冲区,然后在合适的时机异步、批量地执行缓冲区中的内容。但在执行缓冲区的内容时,也是需要在缓冲区加上同步锁的,不然存在并发问题,只不过这样就可以把对锁的竞争从缓存数据转移到对缓冲区上。
ReadBuffer
在Caffeine的内部实现中,为了很好的支持不同的Features(如Eviction,Removal,Refresh,Statistics,Cleanup,Policy等等),扩展了很多子类,它们共同的父类是BoundedLocalCache,而readBuffer就是作为它们共有的属性,即都是用一样的readBuffer,看定义:
1 | final Buffer<Node<K, V>> readBuffer; |
上面提到Caffeine对每次缓存的读操作都会触发afterRead
1 | /** |
重点看BoundedBuffer
1 | /** |
它是一个striped、非阻塞、有界限的buffer,继承于StripedBuffer类。下面看看StripedBuffer的实现:
1 | /** |
这个StripedBuffer设计的思想是跟Striped64类似的,通过扩展结构把竞争热点分离。
具体实现是这样的,StripedBuffer维护一个Buffer[]数组,每个元素就是一个RingBuffer,每个线程用自己threadLocalRandomProbe属性作为hash值,这样就相当于每个线程都有自己“专属”的RingBuffer,就不会产生竞争啦,而不是用key的hashCode作为hash值,因为会产生热点数据问题。
看看StripedBuffer的属性
1 |
|
offer方法,当没初始化或存在竞争时,则扩容为2倍。
实际是调用RingBuffer的offer方法,把数据追加到RingBuffer后面。
1 |
|
最后看看RingBuffer,注意RingBuffer是BoundedBuffer的内部类。
1 |
|
注意,ring buffer的size(固定是16个)是不变的,变的是head和tail而已。
总的来说ReadBuffer有如下特点:
- 使用 Striped-RingBuffer来提升对buffer的读写
- 用thread的hash来避开热点key的竞争
- 允许写入的丢失
WriteBuffer
writeBuffer跟readBuffer不一样,主要体现在使用场景的不一样。本来缓存的一般场景是读多写少的,读的并发会更高,且afterRead显得没那么重要,允许延迟甚至丢失。写不一样,写afterWrite不允许丢失,且要求尽量马上执行。Caffeine使用MPSC(Multiple Producer / Single Consumer)作为buffer数组,实现在MpscGrowableArrayQueue类,它是仿照JCTools的MpscGrowableArrayQueue来写的。
MPSC允许无锁的高并发写入,但只允许一个消费者,同时也牺牲了部分操作。
MPSC我打算另外分析,这里不展开了。
TimerWheel
除了支持expireAfterAccess和expireAfterWrite之外(Guava Cache也支持这两个特性),Caffeine还支持expireAfter。因为expireAfterAccess和expireAfterWrite都只能是固定的过期时间,这可能满足不了某些场景,譬如记录的过期时间是需要根据某些条件而不一样的,这就需要用户自定义过期时间。
先看看expireAfter的用法
1 | private static LoadingCache<String, String> cache = Caffeine.newBuilder() |
通过自定义过期时间,使得不同的key可以动态的得到不同的过期时间。
注意,我把expireAfterAccess和expireAfterWrite注释了,因为这两个特性不能跟expireAfter一起使用。
而当使用了expireAfter特性后,Caffeine会启用一种叫“时间轮”的算法来实现这个功能。更多关于时间轮的介绍,可以看我的文章HashedWheelTimer时间轮原理分析。
好,重点来了,为什么要用时间轮?
对expireAfterAccess和expireAfterWrite的实现是用一个AccessOrderDeque双端队列,它是FIFO的,因为它们的过期时间是固定的,所以在队列头的数据肯定是最早过期的,要处理过期数据时,只需要首先看看头部是否过期,然后再挨个检查就可以了。但是,如果过期时间不一样的话,这需要对accessOrderQueue进行排序&插入,这个代价太大了。于是,Caffeine用了一种更加高效、优雅的算法-时间轮。
时间轮的结构:
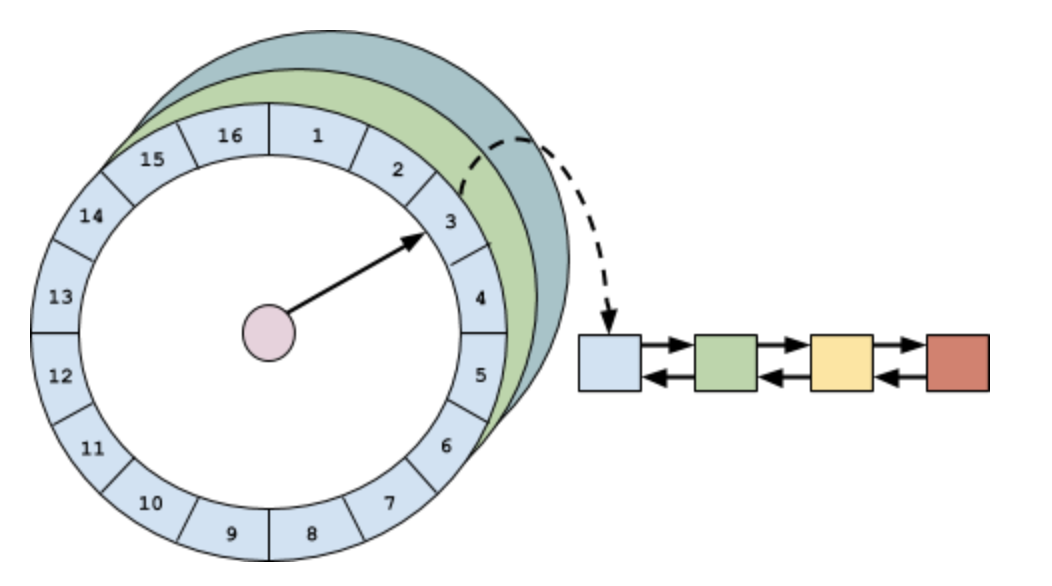
因为在我的对时间轮分析的文章里已经说了时间轮的原理和机制了,所以我就不展开Caffeine对时间轮的实现了。
Caffeine对时间轮的实现在TimerWheel,它是一种多层时间轮(hierarchical timing wheels )。
看看元素加入到时间轮的schedule方法:
1 | /** |
###其他
Caffeine还有其他的优化性能的手段,如使用软引用和弱引用、消除伪共享、CompletableFuture异步等等。
总结
Caffeien是一个优秀的本地缓存,通过使用W-TinyLFU算法, 高性能的readBuffer和WriteBuffer,时间轮算法等,使得它拥有高性能,高命中率(near optimal),低内存占用等特点。