背景
在分层的代码架构中,层与层之间的对象避免不了要做很多转换、赋值等操作,这些操作重复且繁琐,于是乎催生出很多工具来优雅,高效地完成这个操作,有BeanUtils、BeanCopier、Dozer、Orika等等,本文将讲述上面几个工具的使用、性能对比及原理分析。
性能分析
其实这几个工具要做的事情很简单,而且在使用上也是类似的,所以我觉得先给大家看看性能分析的对比结果,让大家有一个大概的认识。
我是使用JMH来做性能分析的,代码如下:
要复制的对象比较简单,包含了一些基本类型;有一次warmup,因为一些工具是需要“预编译”和做缓存的,这样做对比才会比较客观;分别复制1000、10000、100000个对象,这是比较常用数量级了吧。
1 | (Mode.AverageTime) |
在我macbook下运行后的结果如下:
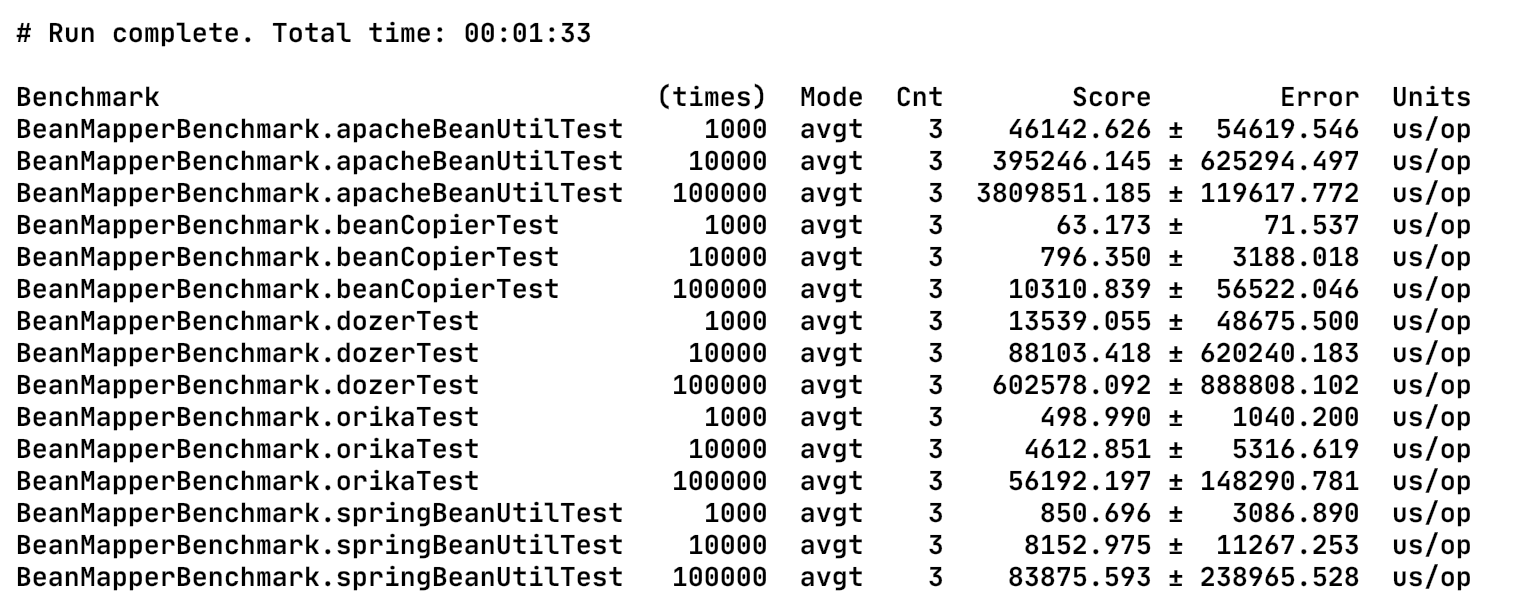
Score表示的是平均运行时间,单位是微秒。从执行效率来看,可以看出 beanCopier > orika > springBeanUtil > dozer > apacheBeanUtil。这样的结果跟它们各自的实现原理有很大的关系,
下面将详细每个工具的使用及实现原理。
Spring的BeanUtils
使用
这个工具可能是大家日常使用最多的,因为是Spring自带的,使用也简单:BeanUtils.copyProperties(sourceVO, targetVO);
原理
Spring BeanUtils的实现原理也比较简答,就是通过Java的Introspector获取到两个类的PropertyDescriptor,对比两个属性具有相同的名字和类型,如果是,则进行赋值(通过ReadMethod获取值,通过WriteMethod赋值),否则忽略。
为了提高性能Spring对BeanInfo和PropertyDescriptor进行了缓存。
(源码基于:org.springframework:spring-beans:4.3.9.RELEASE)
1 | /** |
小结
Spring BeanUtils的实现就是这么简洁,这也是它性能比较高的原因。
不过,过于简洁就失去了灵活性和可扩展性了,Spring BeanUtils的使用限制也比较明显,要求类属性的名字和类型一致,这点在使用时要注意。
Apache的BeanUtils
使用
Apache的BeanUtils和Spring的BeanUtils的使用是一样的:
BeanUtils.copyProperties(targetVO, sourceVO);
要注意,source和target的入参位置不同。
原理
Apache的BeanUtils的实现原理跟Spring的BeanUtils一样,也是主要通过Java的Introspector机制获取到类的属性来进行赋值操作,对BeanInfo和PropertyDescriptor同样有缓存,但是Apache BeanUtils加了一些不那么使用的特性(包括支持Map类型、支持自定义的DynaBean类型、支持属性名的表达式等等)在里面,使得性能相对Spring的BeanUtils来说有所下降。
(源码基于:commons-beanutils:commons-beanutils:1.9.3)
1 | public void copyProperties(final Object dest, final Object orig) |
小结
Apache BeanUtils的实现跟Spring BeanUtils总体上类似,但是性能却低很多,这个可以从上面性能比较看出来。阿里的Java规范是不建议使用的。
BeanCopier
使用
BeanCopier在cglib包里,它的使用也比较简单:
1 |
|
只需要预先定义好要转换的source类和target类就好了,可以选择是否使用Converter,这个下面会说到。
在上面的性能测试中,BeanCopier是所有中表现最好的,那么我们分析一下它的实现原理。
原理
BeanCopier的实现原理跟BeanUtils截然不同,它不是利用反射对属性进行赋值,而是直接使用cglib来生成带有的get/set方法的class类,然后执行。由于是直接生成字节码执行,所以BeanCopier的性能接近手写
get/set。
BeanCopier.create方法
1 | public static BeanCopier create(Class source, Class target, boolean useConverter) { |
这里的意思是用KEY_FACTORY创建一个BeanCopier出来,然后调用create方法来生成字节码。
KEY_FACTORY其实就是用cglib通过BeanCopierKey接口生成出来的一个类
1 | private static final BeanCopierKey KEY_FACTORY = |
通过设置
1 | System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "path"); |
可以让cglib输出生成类的class文件,我们可以反编译看看里面的代码
下面是KEY_FACTORY的类
1 | public class BeanCopier$BeanCopierKey$$KeyFactoryByCGLIB$$f32401fd extends KeyFactory implements BeanCopierKey { |
继续跟踪Generator.create方法,由于Generator是继承AbstractClassGenerator,这个AbstractClassGenerator是cglib用来生成字节码的一个模板类,Generator的super.create其实调用
AbstractClassGenerator的create方法,最终会调用到Generator的模板方法generateClass方法,我们不去细究AbstractClassGenerator的细节,重点看generateClass。
这个是一个生成java类的方法,理解起来就好像我们平时写代码一样。
1 | public void generateClass(ClassVisitor v) { |
即使没有使用过cglib也能读懂生成代码的流程吧,我们看看没有使用useConverter的情况下生成的代码:
1 | public class Object$$BeanCopierByCGLIB$$d1d970c8 extends BeanCopier { |
在对比上面生成代码的代码是不是阔然开朗了。
再看看使用useConverter的情况:
1 | public class Object$$BeanCopierByCGLIB$$d1d970c7 extends BeanCopier { |
小结
BeanCopier性能确实很高,但从源码可以看出BeanCopier只会拷贝名称和类型都相同的属性,而且如果一旦使用Converter,BeanCopier只使用Converter定义的规则去拷贝属性,所以在convert方法中要考虑所有的属性。
Dozer
使用
上面提到的BeanUtils和BeanCopier都是功能比较简单的,需要属性名称一样,甚至类型也要一样。但是在大多数情况下这个要求就相对苛刻了,要知道有些VO由于各种原因不能修改,有些是外部接口SDK的对象,
有些对象的命名规则不同,例如有驼峰型的,有下划线的等等,各种什么情况都有。所以我们更加需要的是更加灵活丰富的功能,甚至可以做到定制化的转换。
Dozer就提供了这些功能,有支持同名隐式映射,支持基本类型互相转换,支持显示指定映射关系,支持exclude字段,支持递归匹配映射,支持深度匹配,支持Date to String的date-formate,支持自定义转换Converter,支持一次mapping定义多处使用,支持EventListener事件监听等等。不仅如此,Dozer在使用方式上,除了支持API,还支持XML和注解,满足大家的喜好。更多的功能可以参考这里
由于其功能很丰富,不可能每个都演示,这里只是给个大概认识,更详细的功能,或者XML和注解的配置,请看官方文档。
1 | private Mapper dozerMapper; |
原理
Dozer的实现原理本质上还是用反射/Introspector那套,但是其丰富的功能,以及支持多种实现方式(API、XML、注解)使得代码看上去有点复杂,在翻阅代码时,我们大可不必理会这些类,只需要知道它们大体的作用就行了,重点关注核心流程和代码的实现。下面我们重点看看构建mapper的build方法和实现映射的map方法。
build方法很简单,它是一个初始化的动作,就是通过用户的配置来构建出一系列后面要用到的配置对象、上下文对象,或其他封装对象,我们不必深究这些对象是怎么实现的,从名字上我们大概能猜出这些对象是干嘛,负责什么就可以了。
1 | DozerBeanMapper(List<String> mappingFiles, |
map方法是映射对象的过程,其入口是MappingProcessor的mapGeneral方法
1 | private <T> T mapGeneral(Object srcObj, final Class<T> destClass, final T destObj, final String mapId) { |
一般情况下createByCreationDirectiveAndMap方法会一直调用到mapFromFieldMap方法,而在没有自定义converter的情况下会调用mapOrRecurseObject方法
大多数情况下字段的映射会在这个方法做一般的解析
1 | private Object mapOrRecurseObject(Object srcObj, Object srcFieldValue, Class<?> destFieldType, FieldMap fieldMap, Object destObj) { |
mapCustomObject方法。其实你会发现这个方法最重要的一点就是做递归处理,无论是最后调用createByCreationDirectiveAndMap还是mapToDestObject方法。
1 | private Object mapCustomObject(FieldMap fieldMap, Object destObj, Class<?> destFieldType, String destFieldName, Object srcFieldValue) { |
小结
Dozer功能强大,但底层还是用反射那套,所以在性能测试中它的表现一般,仅次于Apache的BeanUtils。如果不追求性能的话,可以使用。
Orika
Orika可以说是几乎集成了上述几个工具的优点,不仅具有丰富的功能,底层使用Javassist生成字节码,运行 效率很高的。
使用
Orika基本支持了Dozer支持的功能,这里我也是简单介绍一下Orika的使用,具体更详细的API可以参考User Guide。
1 | private MapperFactory mapperFactory; |
原理
在讲解实现原理时,我们先看看Orika在背后干了什么事情。
通过增加以下配置,我们可以看到Orika在做映射过程中生成mapper的源码和字节码。
1 |
|
用上面的例子,我们看看Orika生成的java代码:
1 | package ma.glasnost.orika.generated; |
这个mapper类就两个方法mapAtoB和mapBtoA,从名字看猜到前者是负责src -> dest的映射,后者是负责dest -> src的映射。
好,我们们看看实现的过程。
Orika的使用跟Dozer的类似,首先通过配置生成一个MapperFactory,再用MapperFacade来作为映射的统一入口,这里MapperFactory和MapperFacade都是单例的。mapperFactory在做配置类映射时,只是注册了ClassMap,还没有真正的生成mapper的字节码,是在第一次调用getMapperFacade方法时才初始化mapper。下面看看getMapperFacade。
(源码基于 ma.glasnost.orika:orika-core:1.5.4)
1 | public MapperFacade getMapperFacade() { |
利用注册的ClassMap信息和MappingContext上下文信息来构造mapper
1 | public synchronized void build() { |
跟踪buildMapper方法
1 | private GeneratedMapperBase buildMapper(ClassMap<?, ?> classMap, boolean isAutoGenerated, MappingContext context) { |
MapperGenerator的build方法
1 | public GeneratedMapperBase build(ClassMap<?, ?> classMap, MappingContext context) { |
生成mapper实例
1 | T instance = (T) compileClass().newInstance(); |
这里的compilerStrategy的默认是用Javassist(你也可以自定义生成字节码的策略)
JavassistCompilerStrategy的compileClass方法
这基本上就是一个使用Javassist的过程,经过前面的各种铺垫(通过配置信息、上下文信息、拼装java源代码等等),终于来到这一步
1 | public Class<?> compileClass(SourceCodeContext sourceCode) throws SourceCodeGenerationException { |
好,mapper类生成了,现在就看在调用MapperFacade的map方法是如何使用这个mapper类的。
其实很简单,还记得生成的mapper是放到mappersRegistry吗,跟踪代码,在resolveMappingStrategy方法根据typeA和typeB在mappersRegistry找到mapper,在调用mapper的mapAtoB或mapBtoA方法即可。
小结
总体来说,Orika是一个功能强大的而且性能很高的工具,推荐使用。
总结
通过对BeanUtils、BeanCopier、Dozer、Orika这几个工具的对比,我们得知了它们的性能以及实现原理。在使用时,我们可以根据自己的实际情况选择,推荐使用Orika。