概要
线程池,大家都很熟悉了,我们在平时应用中也用的很多。对线程池,ThreadPoolExecutor 的实现原理有一定理解后,我们可以把它用的更好,对它的参数有更加深刻的理解,甚至我们可以扩展,监控自己的线程池。
ThreadPoolExecutor实现原理
本文代码基于JDK1.8
线程池相关的类的关系
我们先看看主要的类ThreadPoolExecutor的继承关系
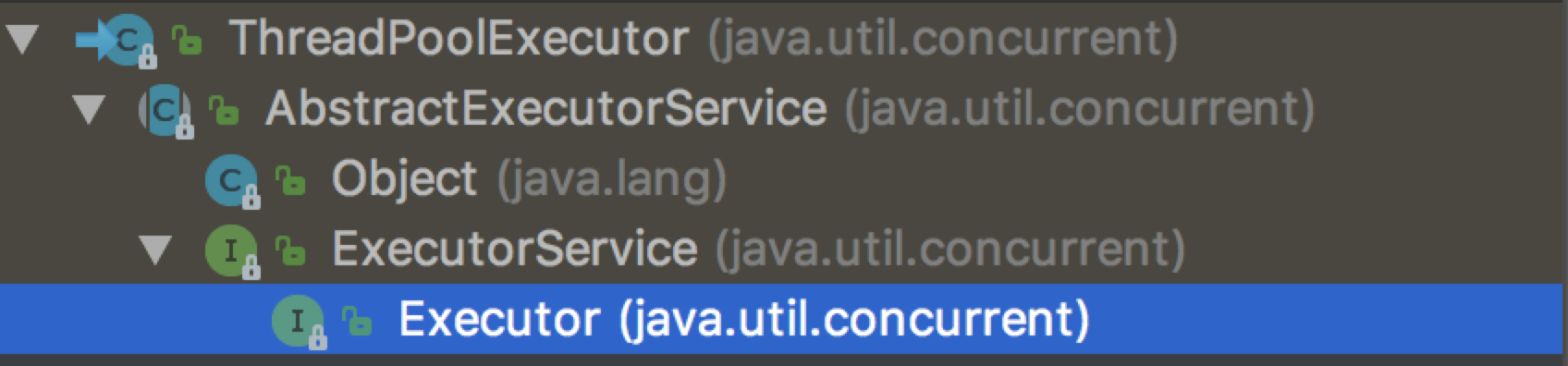
平时可能还有用到的 Executors 类,这是一个工具类,提供
newFixedThreadPool
newCachedThreadPool
newScheduledThreadPool
等静态方法方便我们创建线程池,最终还是调用 ThreadPoolExecutor 来创建的,一般规范不建议直接使用 Executors 来创建线程池。
线程池创建的主流程
线程池的状态
先看看线程池的状态有哪些,对它有初步的理解
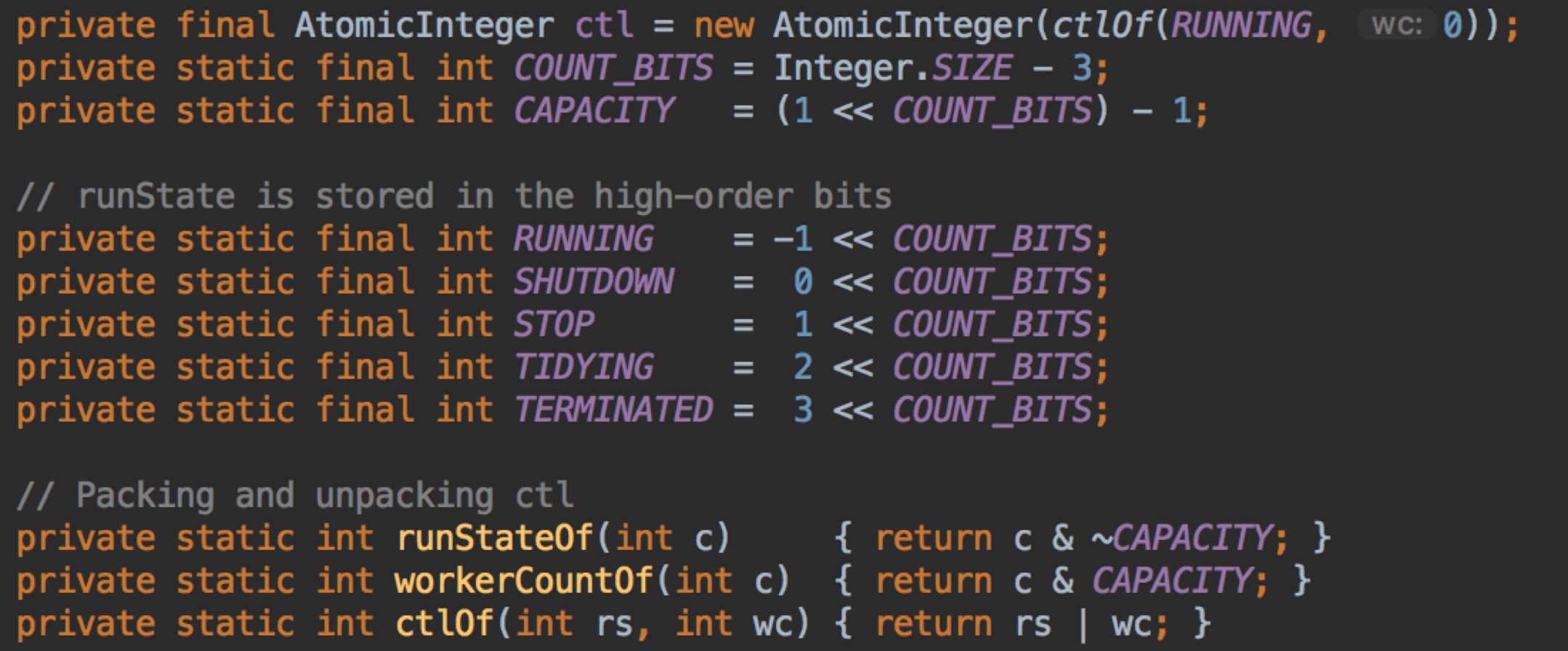
线程池的状态和运行的线程数只用了一个 int,其中高3位表示状态,低29位表示线程数。
状态表示的意思和状态之间的转换:
RUNNING - 可以接受新的任务,及执行队列中的任务
SHUTDOWN - 不接受新的任务,但会继续执行队列中的任务
STOP - 不接受新的任务,既不会执行队列中的任务,还会中断执行中的任务
TIDYING - 全部任务已经终止,且线程数为0
TERMINATED - 线程池完全终止
RUNNING -> SHUTDOWN - 执行了 shutdown()
(RUNNING or SHUTDOWN) -> STOP - 执行了shutdownNow()
SHUTDOWN -> TIDYING - 队列和线程为空
STOP -> TIDYING - 线程为空
TIDYING -> TERMINATED - terminated() 这个勾子方法执行完毕
线程池的创建
ThreadPoolExecutor 的构造函数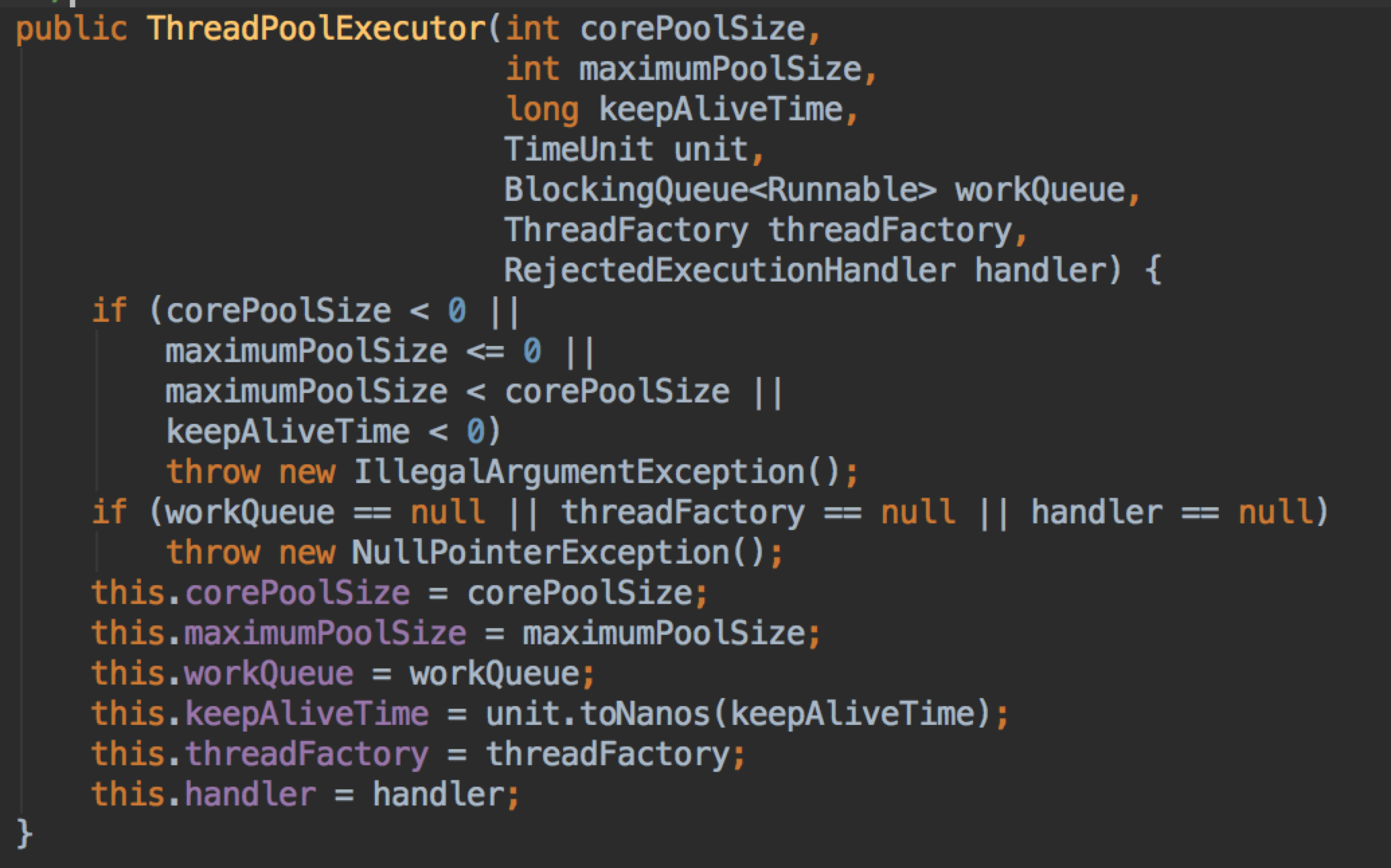
线程池的创建只是初始化了一些参数,但理解好这些参数对我们使用线程池很有帮助。
corePoolSize - 核心线程数,除非 allowCoreThreadTimeOut 为 true(默认false),否则即使没有任务,也会维持这么多线程。
maximumPoolSize - 最大线程数,corePoolSize 满了的话,会把任务放到队列,如果队列满了的话(假设队列有界),就会继续创建线程直到 maximumPoolSize,如果超过 maximumPoolSize 则会执行 reject 策略。
workQueue - 用来存放任务的队列,是一个 BlockingQueue,常用的有 LinkedBlockingQueue,ArrayBlockingQueue,SynchronousQueue。
keepAliveTime - 空闲线程的存活时间,如果当前线程数 > corePoolSize,且某个线程空闲了这么多时间(没有获取到任务并运行),那么这个线程会被 remove 掉。
unit - keepAliveTime 的单位,内部会统一转换成 nanos
threadFactory - 用来创建线程的 ThreadFactory,主要用来给线程命名(方便查看日志),设置 daemon,优先级和 group 等,Executors 有 DefaultThreadFactory 这个默认实现。
handler - reject 具体执行策略,reject 的条件上面已经说了,一般内置有以下几个,也可以自己实现
CallerRunsPolicy - 不使用线程池的线程执行该任务,直接用当前执行任务(例如 main 线程)
AbortPolicy - 直接抛异常
DiscardPolicy - 无视不做处理,相当于抛弃掉
DiscardOldestPolicy - 将队列头的任务取出来抛弃掉,然后运行当前任务
线程池的执行
一般我们使用 ExecutorService 的 submit 方法来使用线程池执行一个任务,这个方法调用到 AbstractExecutorService
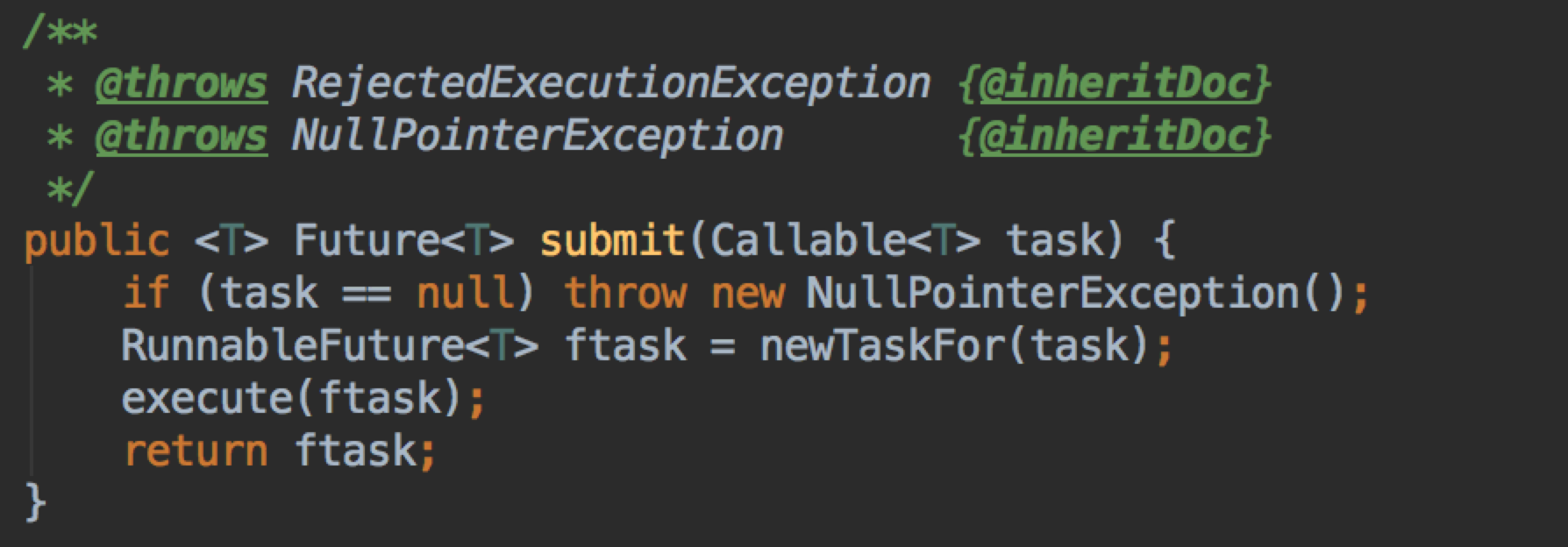
这里我们看到所有 task 无论是 Callable 还是 Runnable 的都会包装成一个 RunnableFuture 也就是 FutureTask,返回给我们。
execute方法
重点看 execute 方法,调用了 ThreadPoolExecutor 的 execute
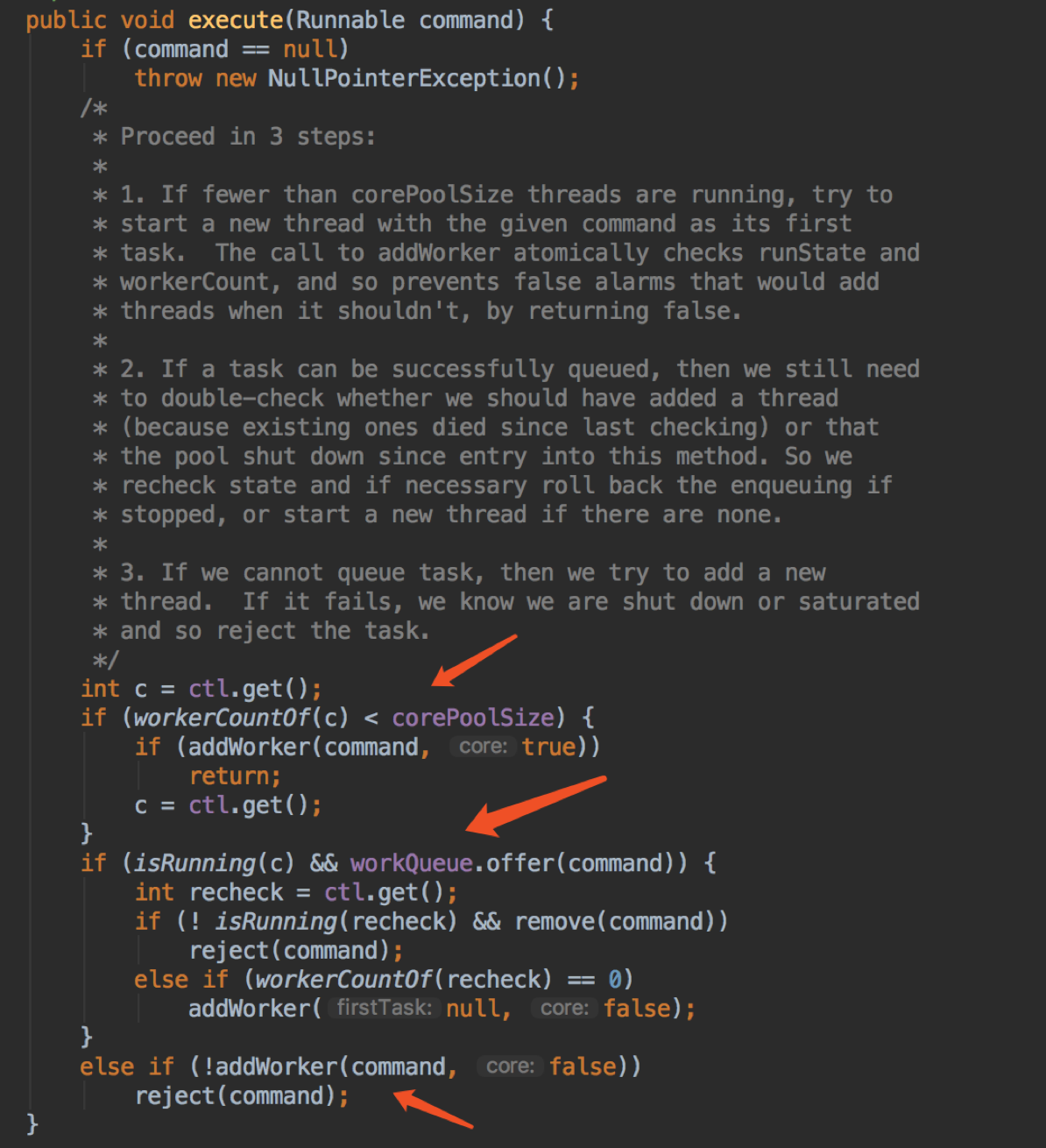
我们分三种情形来看,每个是一个 if 条件:
第一,当 workCount < corePoolSize 时,直接创建 worker 线程;
第二,如果上面创建失败(可能是线程池正在处于关闭状态,可能是 workCount > corePoolSize 了 - 并发场景),那么这时把任务放入 workQueue 队列;下面的判断是用来防止,线程池不在运行了,就把任务删掉;如果没有线程了就加一个;
第三,来到这步说明上面放队列不成功(可能是队列是有界的,满了),那么就继续创建线程来满足,如果这都创建失败(可能是 > maximumPoolSize)就 reject 了;
addWorker方法
继续看看重点的 addWorker 方法,addWorker 分开两部分来看。
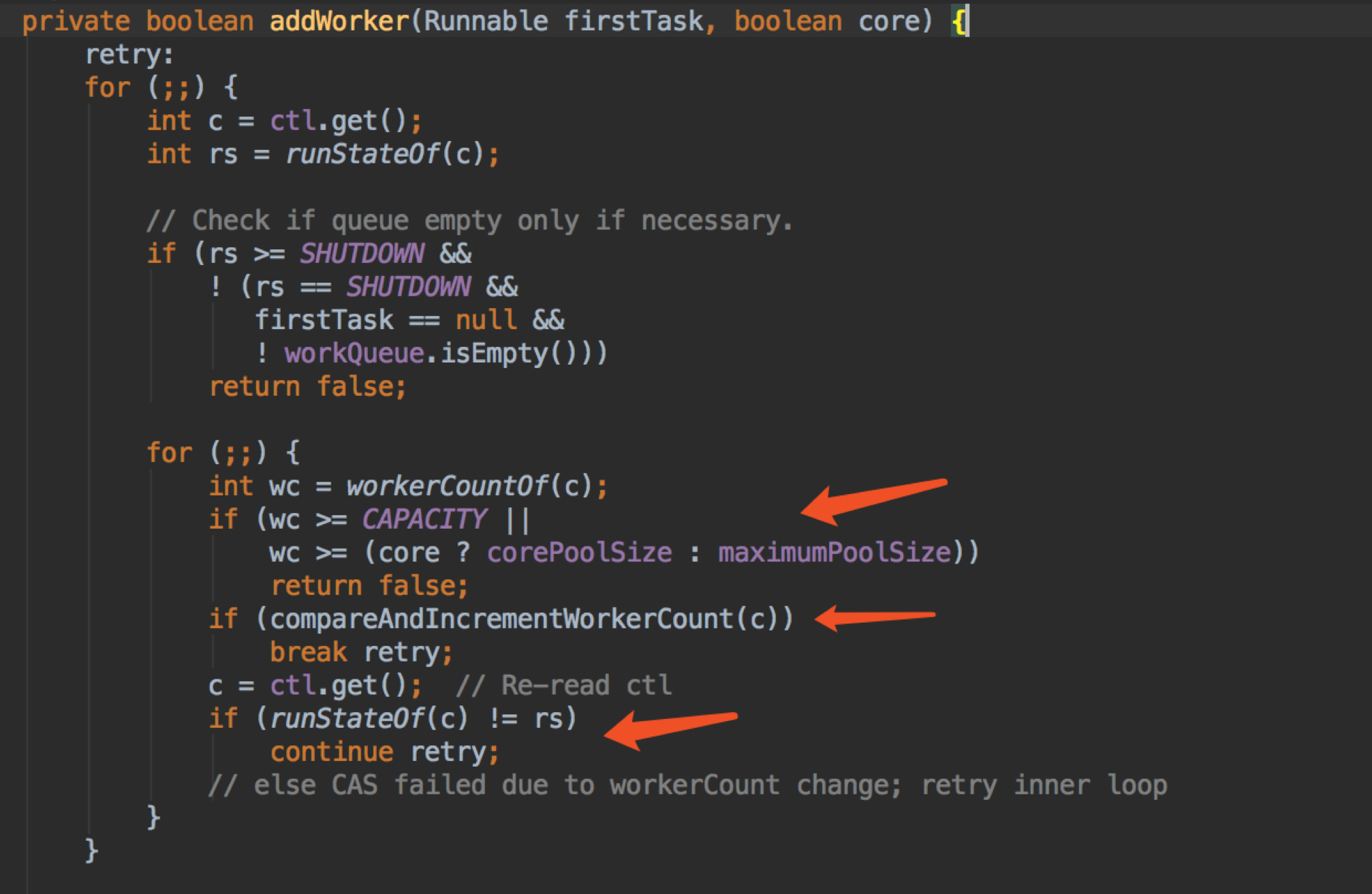
这一步是判断是否可以增加 worker 的重点:
第一,首先开始的判断有点奇怪,我也不是很明白,先认为它是如果状态是 SHUTDOWN 则不允许创建线程;
第二,下面有个 core 参数,true 使用 corePoolSize,false 使用 maximumPoolSize,我们上面说的 execute 方法第一次就是传 true 的,第二次就传 false。所以这里就是对 size 做判断, 如果 >= size 则返回 false,否则 cas 一下,成功了就 break 执行下面的代码;
第三,如果 cas 失败,说明有其他并发竞争,则 cintinue 循环上面的步骤判断。
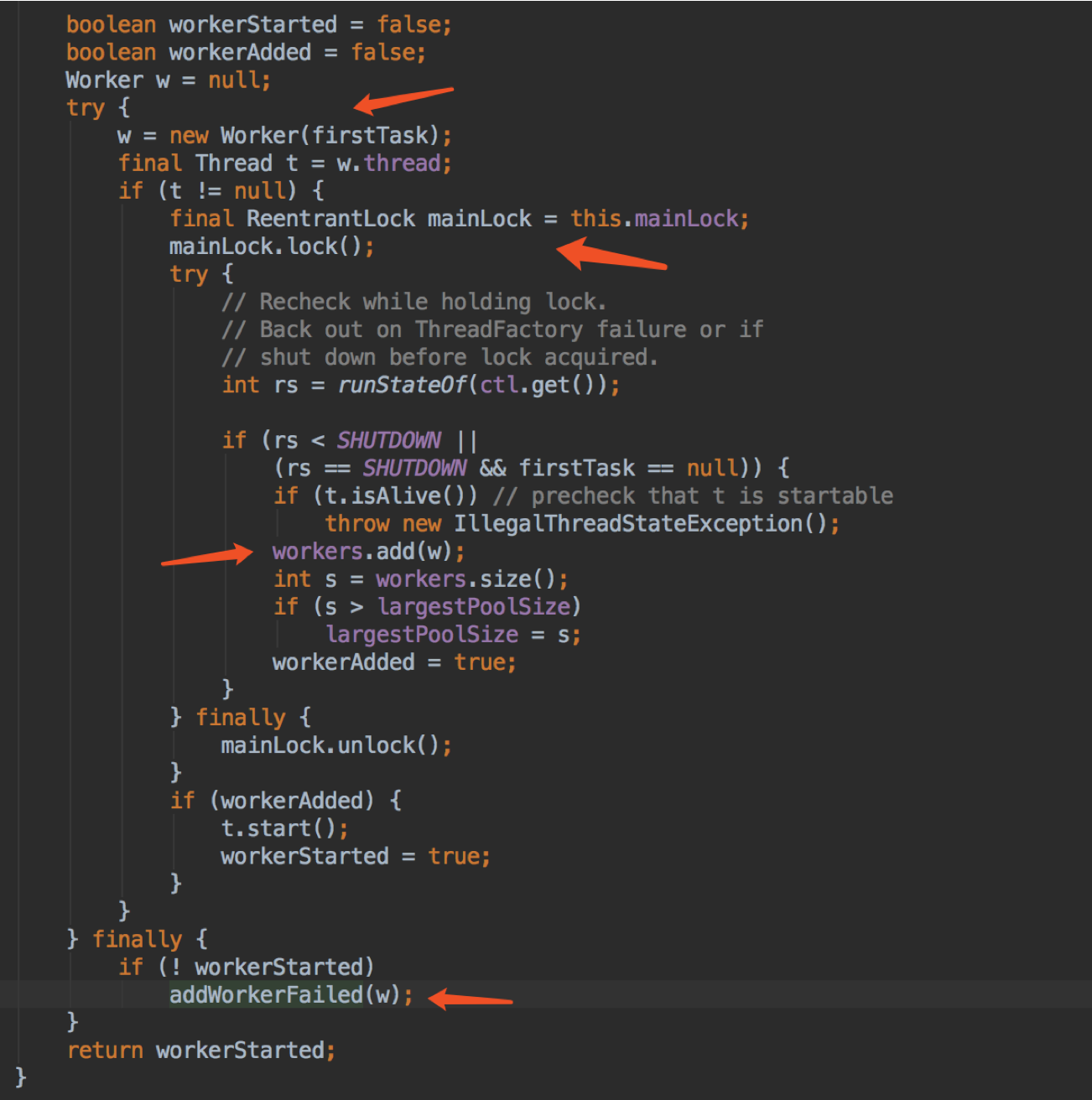
来到这一步说明可以创建 worker 了,这里用了一个全局 lock,来控制创建线程和关闭线程的不能同时做。
可以看到步骤就是 new 一个 worker,add 到 workers 里,workers 是一个 HashSet。

largestPoolSize 来用记录最大的线程数。
如果 workerStarted == false(线程池在关闭或创建 worker 时异常),则会 addWorkerFailed 方法。
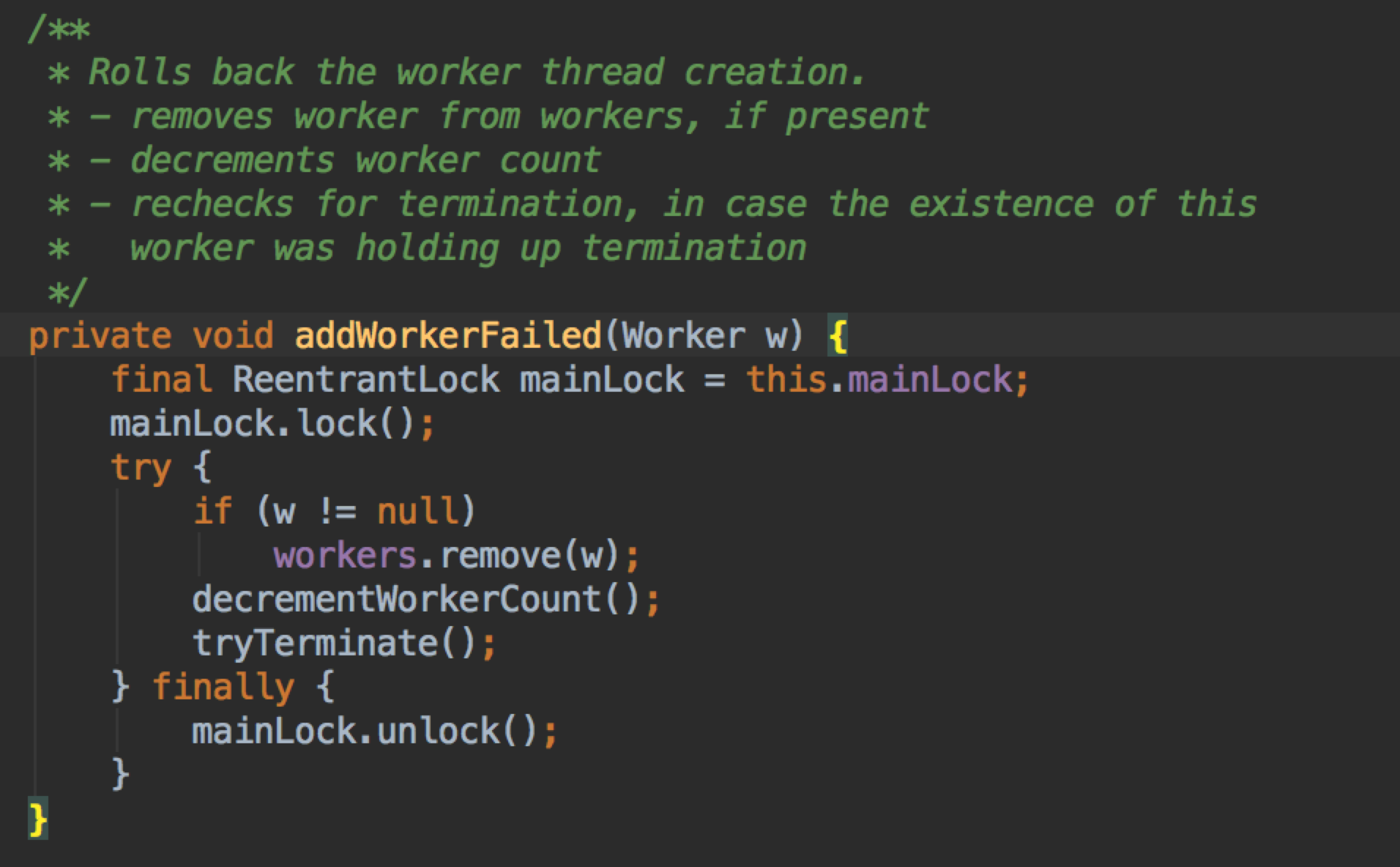
主要就是 remove 掉 worker,扣减计数,这里还会调用 tryTerminate 。
这个方法会在很多地方用到,它的作用就是防止线程池在终止状态这种情形,去终止线程。
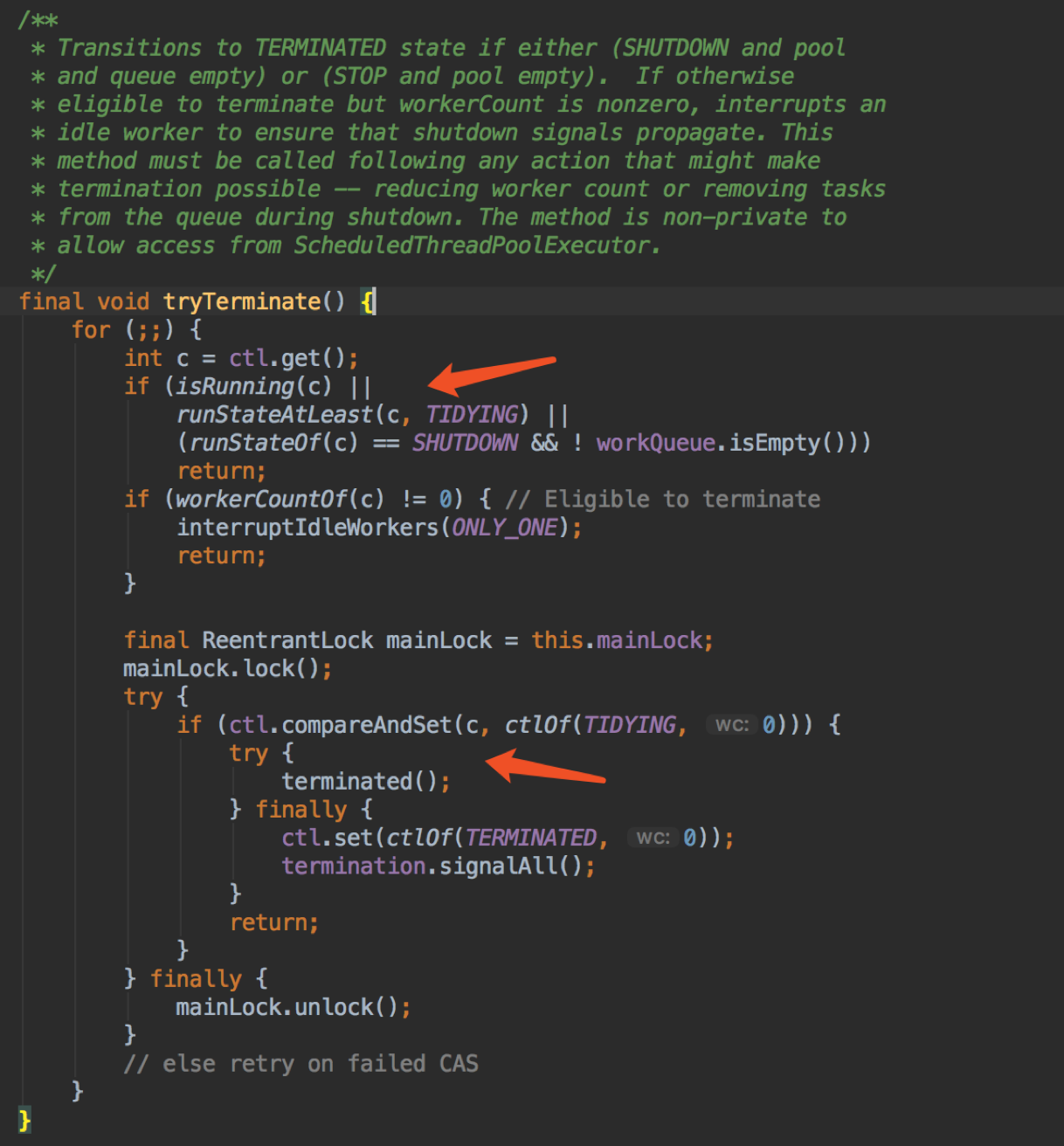
Worker是什么
我们刚刚一直说 worker,那到底 Worker 究竟是什么?我们现在来看看
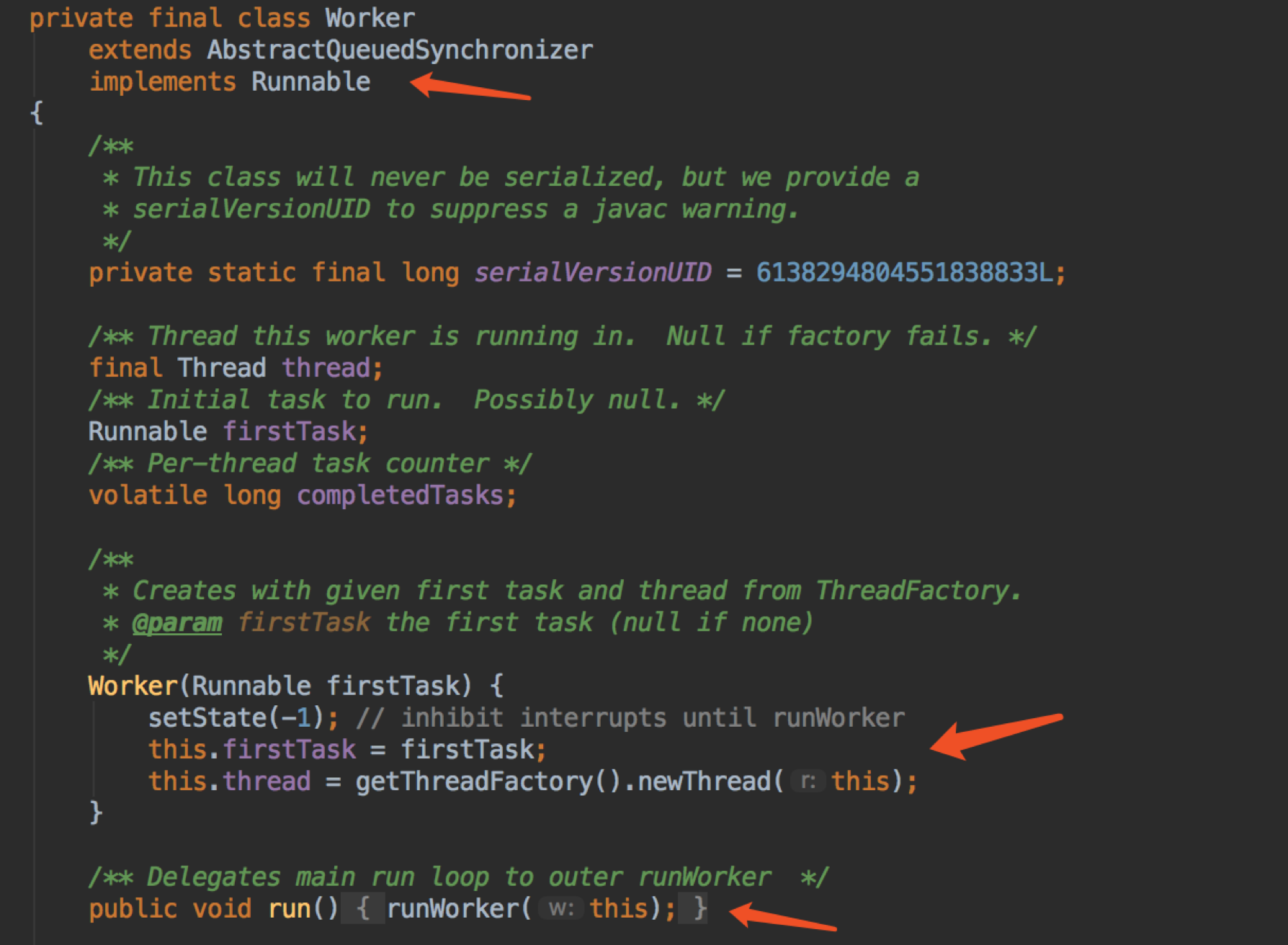
我们可以看到 Worker 是一个 AQS 和 Runnable。
为什么是一个 AQS ?
我们可以结合注释和代码可以得到,worker 在跑任务的时候会 lock 住,在被中断时会 tryLock,利用上锁这一点来区分这个 worker 是否空闲。
Worker 中重写 AQS 的方法。(感概:AQS 真是个简单易用,用于并发控制的好工具!)
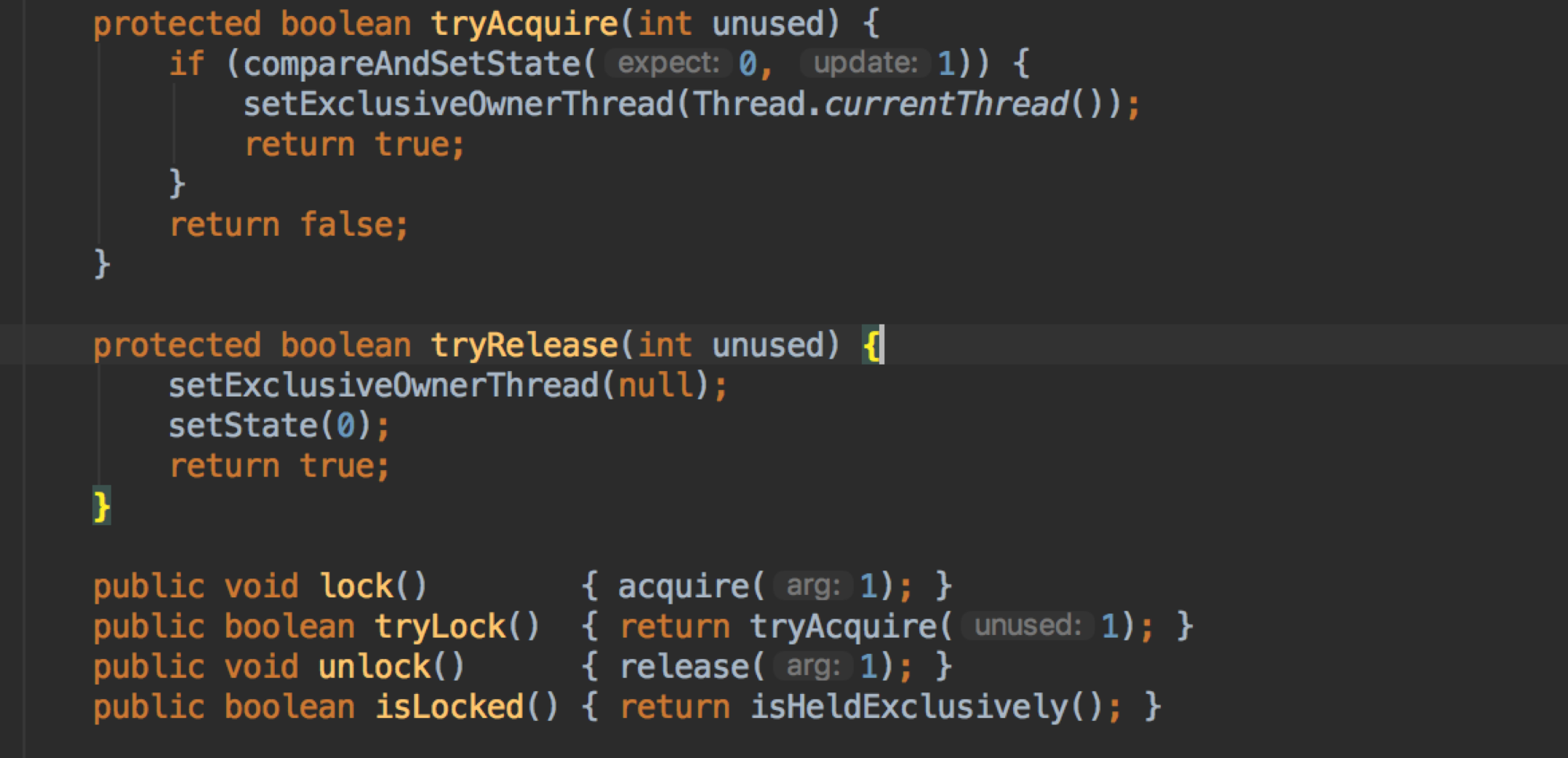
为什么是一个 Runnable ?
我们看看 Worker 的构造函数,在创建 Thread 时把自己 this 传到 thread 的参数,说明 worker 的 thread 跑的是自己,这时我们就知道 worker 的入口了。
Worker 的 run 方法

runWorker方法
重点的 runWorker 方法
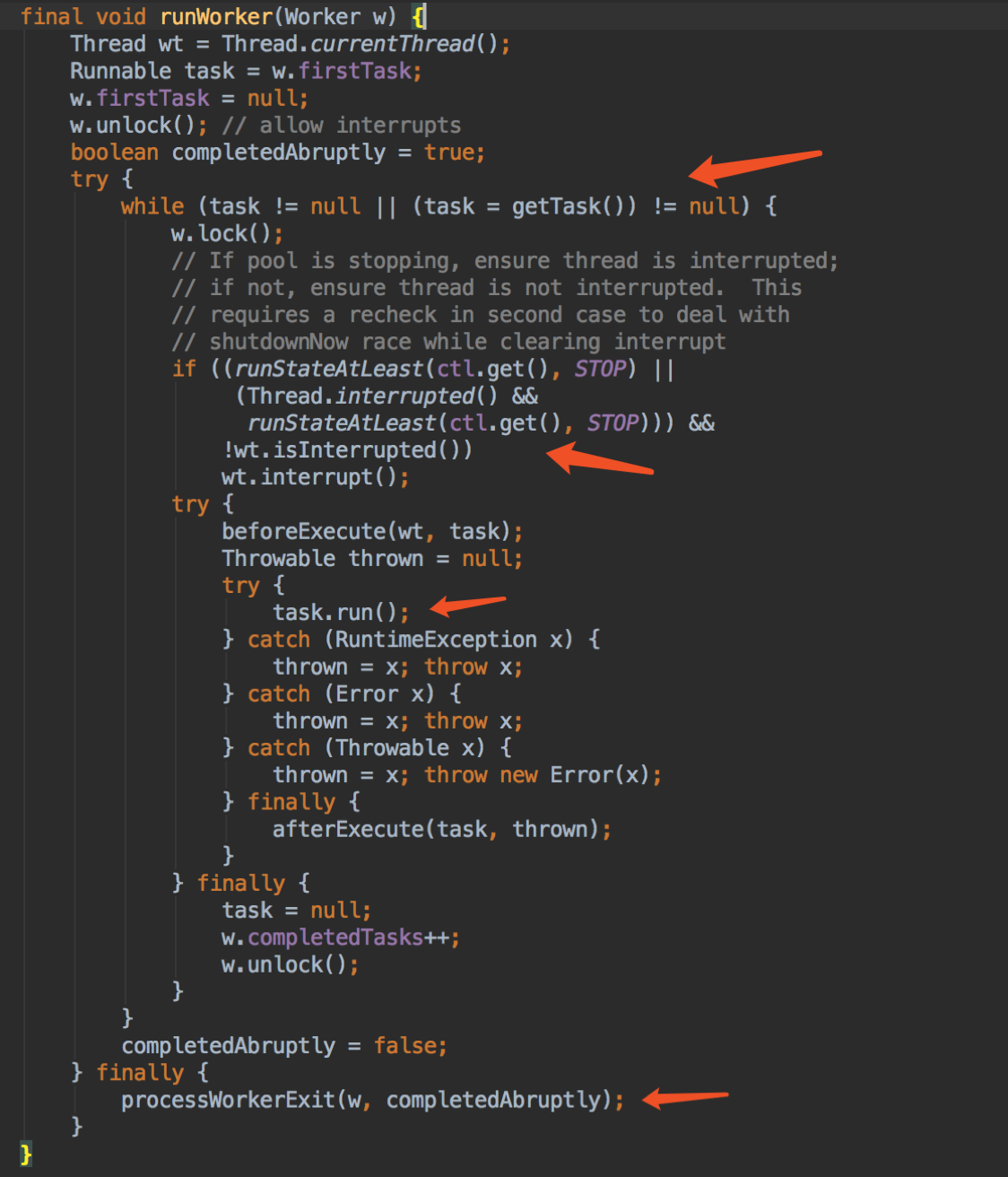
task 可能是传进来的 firstTask 或者 getTask() 获取到的,getTask 也是重点方法,等下讲到;
运行 task 时会上锁,锁的作用我刚刚已经说了;
如果线程池状态是 STOP 则中断线程;
这里放了两个勾子 beforeExecute 和 afterExecute 方法来提供给子类做点事情,一般用于监控或统计线程池的执行情况;
执行任务就直接 task.run() 了,还记得我说过这个 task 是一个 FutureTask,如果run 的时候抛出异常,FutureTask 会 catch 掉不会再 throw(如果大家对 FutureTask 不熟悉就先这样理解),所以这里不会进入 catch,也就是不会 throw x 了。如果 task 不像 FutureTask 一样自己处理掉异常,那就会 throw x 了,那么 worker 的线程就会跳出 while 循环,完成使命,结束自己;
获取不到 task (task 为null)或者循环过程中异常,最后都会执行 processWorkerExit。
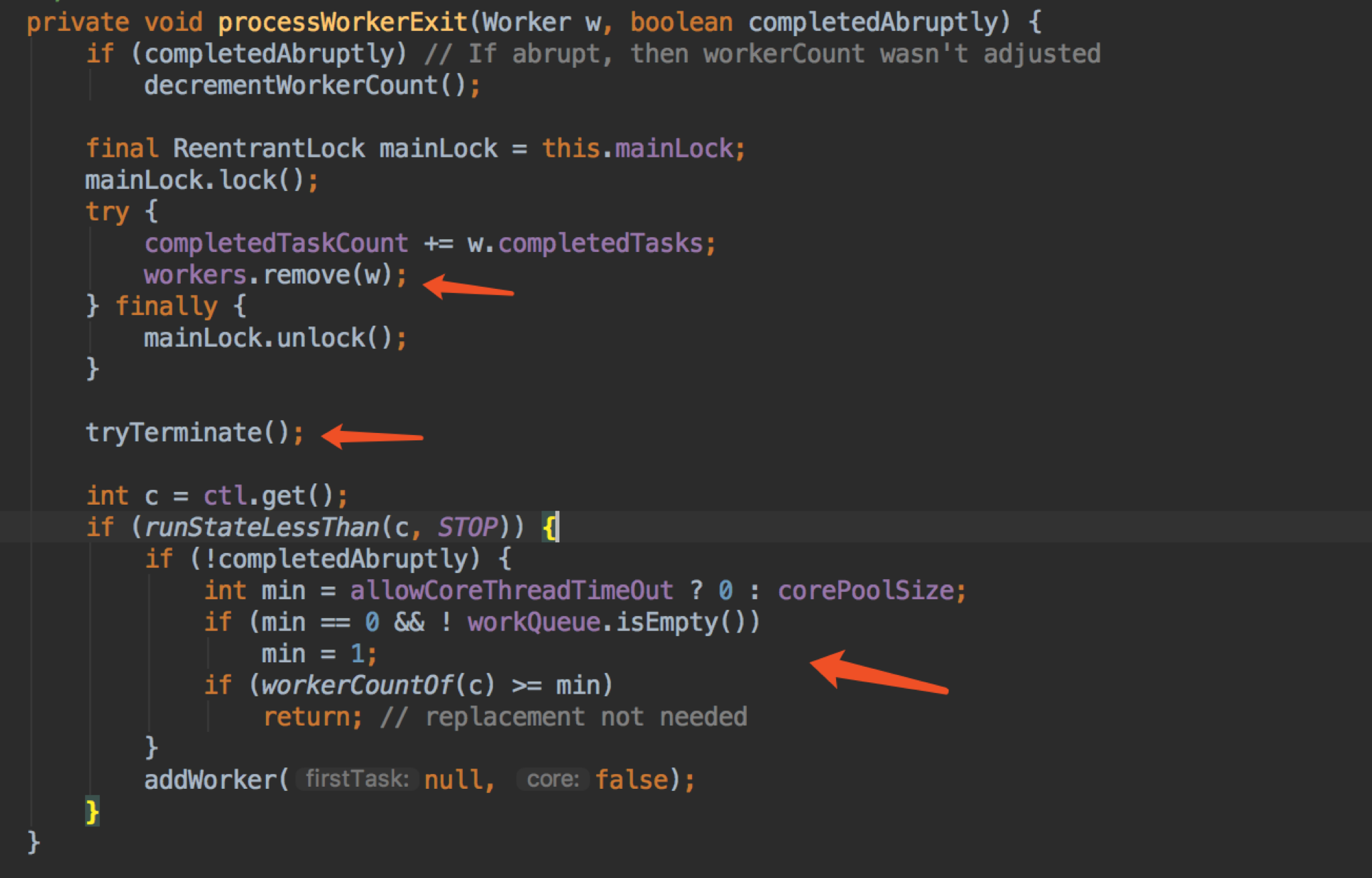
processWorkerExit 的作用主要就是 remove 掉 worker,那么扣减 workCount 呢?好像没有看到。这里用了 completedAbruptly 这一变量来控制是否在 processWorkerExit 扣减 workCount,因为有可能是在 getTask 已经扣减了,那么在 processWorkerExit 就不用重复扣减。我们结合 runWorker 来看看,分两种情况:
1、如果 firstTask 为 null,那么会走到 getTask 方法,如果 getTask 返回 null,那么说明已经是扣减了,这时退出循环,completedAbruptly = false,不用重复扣减。
2、如果 firstTask 不为 null
(1)执行 firstTask 正常结束,然后循环,走到 getTask,如果返回 task 为 null,那么 completedAbruptly = false,不用重复扣减。
(2)执行 firstTask 执行异常,这时 completedAbruptly = true,需要扣减
这里我们又看到 tryTerminate 了;
下面的判断主要是尝试去增加一个 worker,因为你 remove 掉了一个,如果条件允许,那就加回一个呗。
getTask方法
看看重点的 getTask 方法
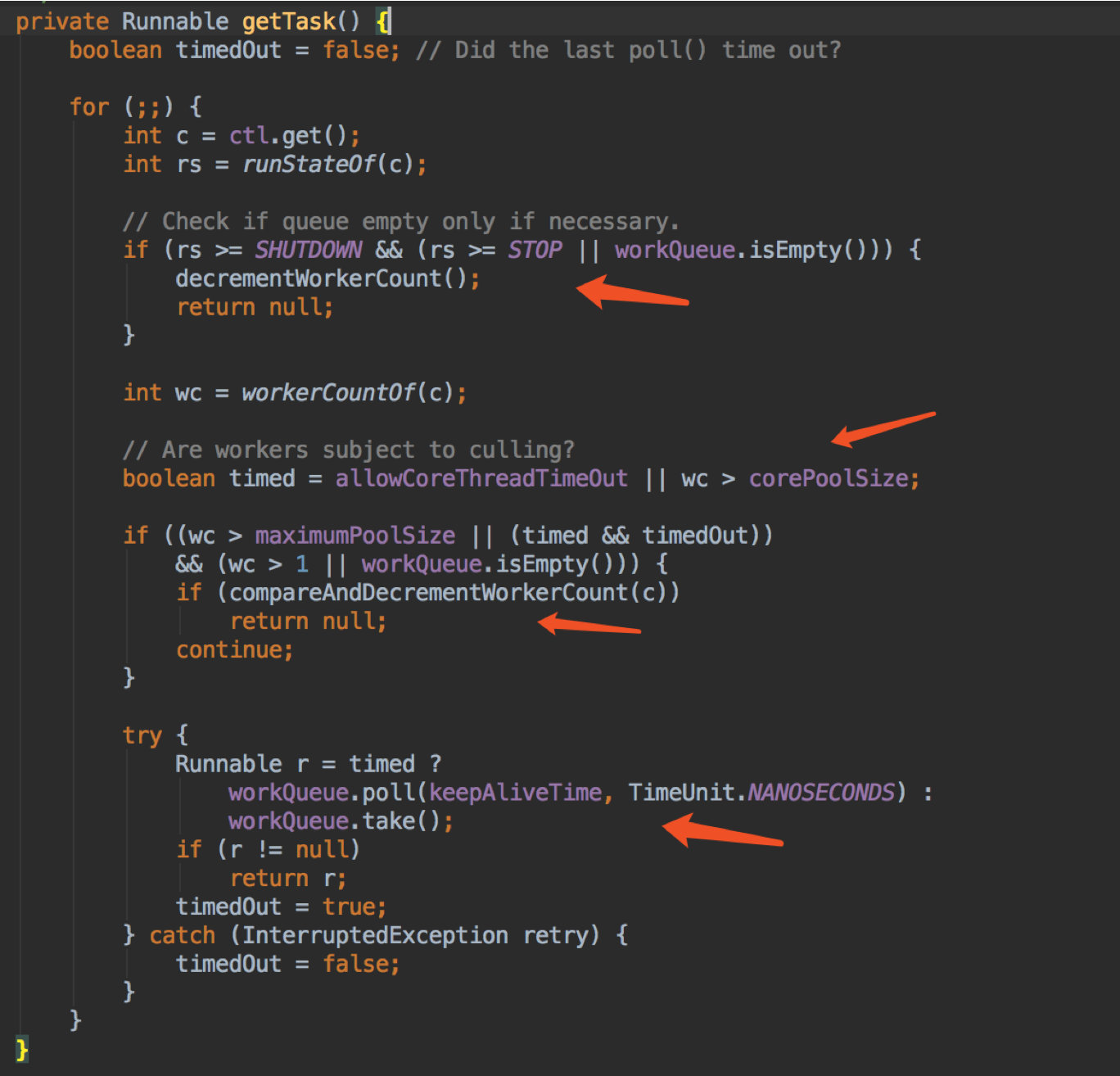
在 getTask 时如果发现时线程池在关闭状态,那么就需要停止获取任务了;
如果 wc > maximumPoolSize,超过了最大 size 了,就去 cas 扣减 workCount 一下,成功就返回 null;
如果 wc > corePoolSize(小于 maximumPoolSize),且 timedOut 的话,说明这个 worker 也有点“多余”,也去扣减 workCount。注意这里对 timedOut 的判断,通过 queue 的定时 poll 方法,时间是线程池的构造参数 keepAliveTime,如果过了这么久都还没获取 task,说明 queue 是空的,有空闲的线程,那就把这个 worker remove 掉吧;
如果 wc < corePoolSize 的话,那就调用 queue 的 take 方法一直阻塞获取 task;
还有 allowCoreThreadTimeOut 参数,它的意思是忽略对 corePoolSize 的判断。
关闭线程池
上面已经把线程的创建和执行基本说得7788了,我们看看关闭线程池是如何做的,其实在上面的很多方法中,都看到很多对如 SHUTDOWN 的判断了。主要有 shutdown 和 shutdownNow 这两个方法。
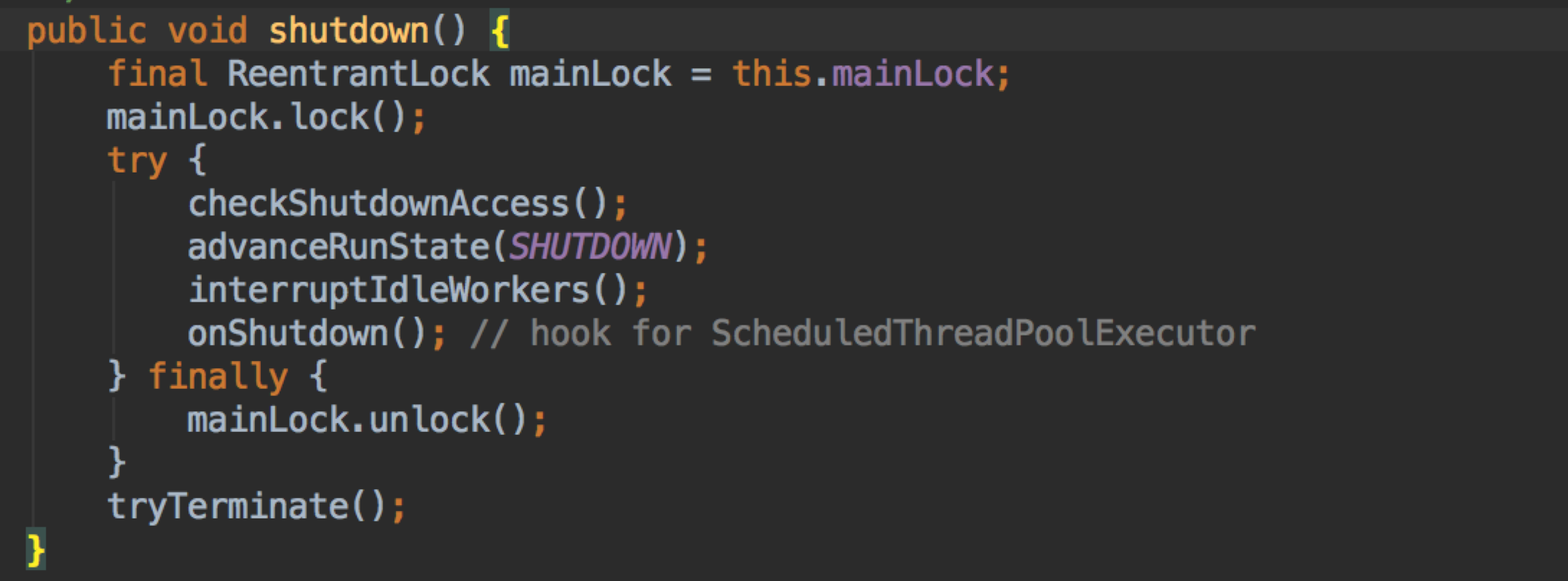
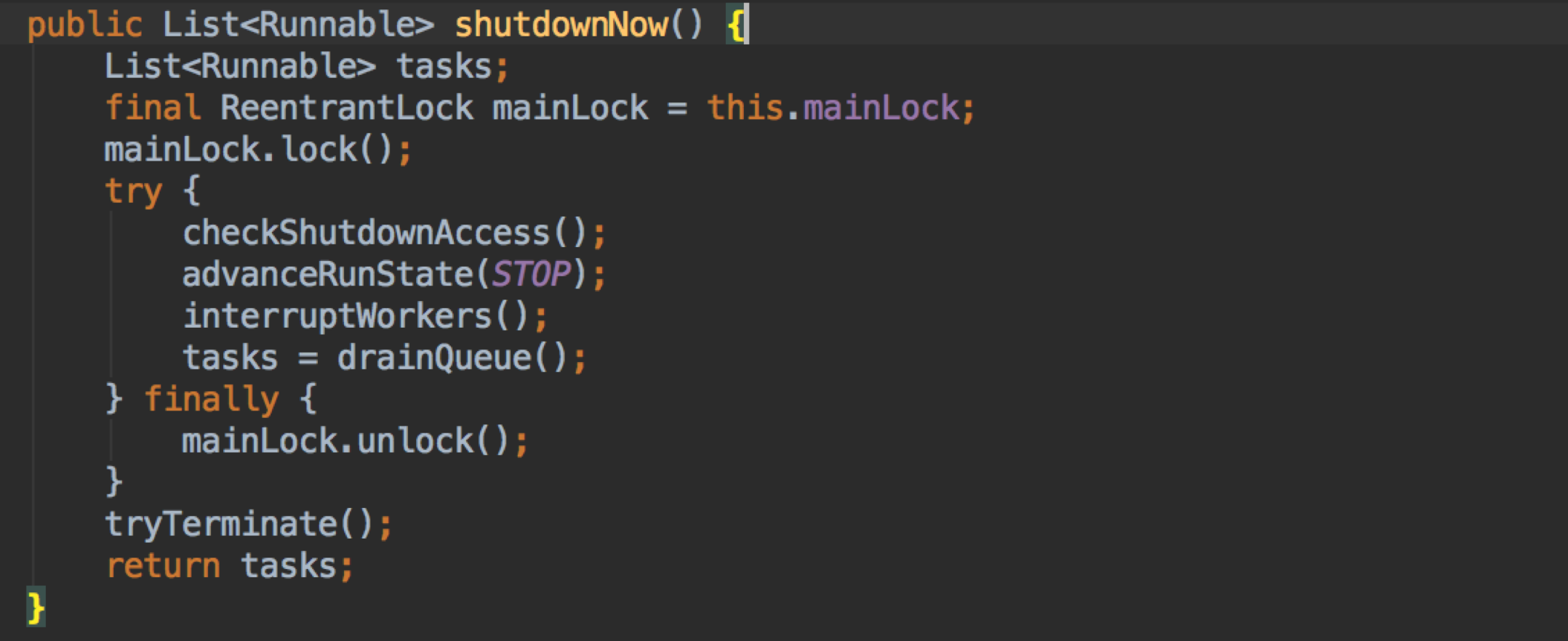
这两个方法很相似,从名字来看 shutdown 显得更加的柔性,实际也是。
shutdown –
不接受新的 task,在运行和已经在队列的 task 可以继续运行;
把状态改为 SHUTDOWN;
中断空闲 worker,这个在上面已经提到过了,用锁对是否空闲做判断。
interruptIdleWorkers 打断空闲的线程
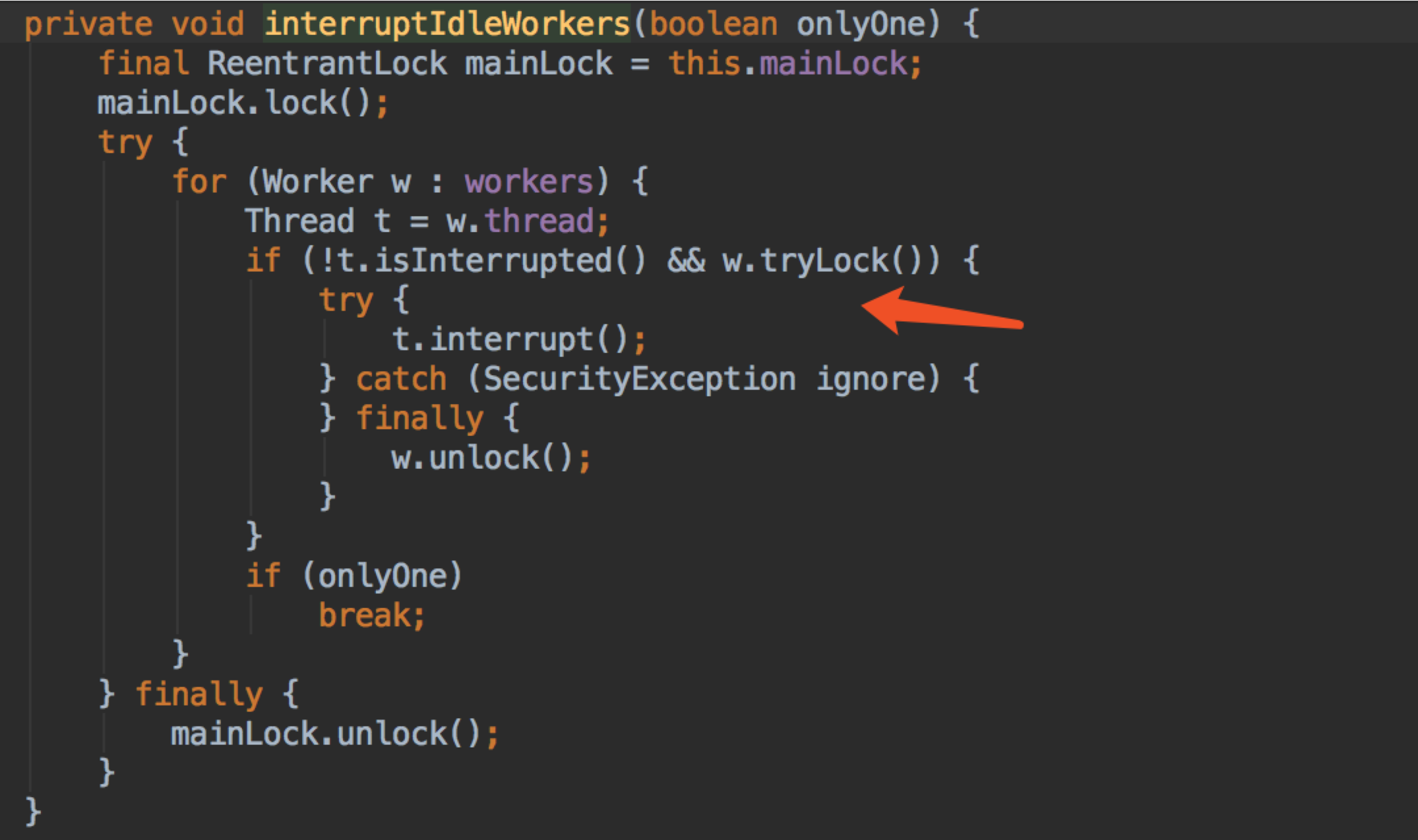
这里还有个 onShutdown 勾子方法。
shutdownNow –
不接受新的 task,中断已经在运行的线程,清空队列;
把状态改为 STOP;
强制中断所有在运行 worker 的线程;
drainQueue,相当于把队列的 task 丢弃掉;
总结
线程池ThreadPoolExecutor实现的原理,就是用 Worker 线程不停得取出队列中的任务来执行,根据参数对任务队列和 Workers 做限制,回收,调整。
参考资料
http://www.jianshu.com/p/87bff5cc8d8c
https://javadoop.com/post/java-thread-pool