概要
本文主要补充对HashMap的一些理解、分析。相信大家对HashMap都很熟悉,但是其中的一些细节上的设计、思想,往往会被大家忽略,这些都是构成HashMap的重要组成部分,包括有“如何做hash”,“resize后如何保证key的位置”,“resize在高并发下引发的死循环”,“为什么 TREEIFY_THRESHOLD = 8?”,“允许null值的原因”等等,希望有你感兴趣的。
补充对HashMap的几点理解
为什么JDK 1.8后链表改为红黑树
当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),如果 hash 冲突严重,由这里产生的性能问题尤为突显。
JDK 1.8 中引入了红黑树,当链表长度 >= TREEIFY_THRESHOLD(8) & tab.length >= MIN_TREEIFY_CAPACITY(64)时,链表就会转化为红黑树,它的查找时间复杂度为 O(logn),以此来优化这个问题。
如何做hash
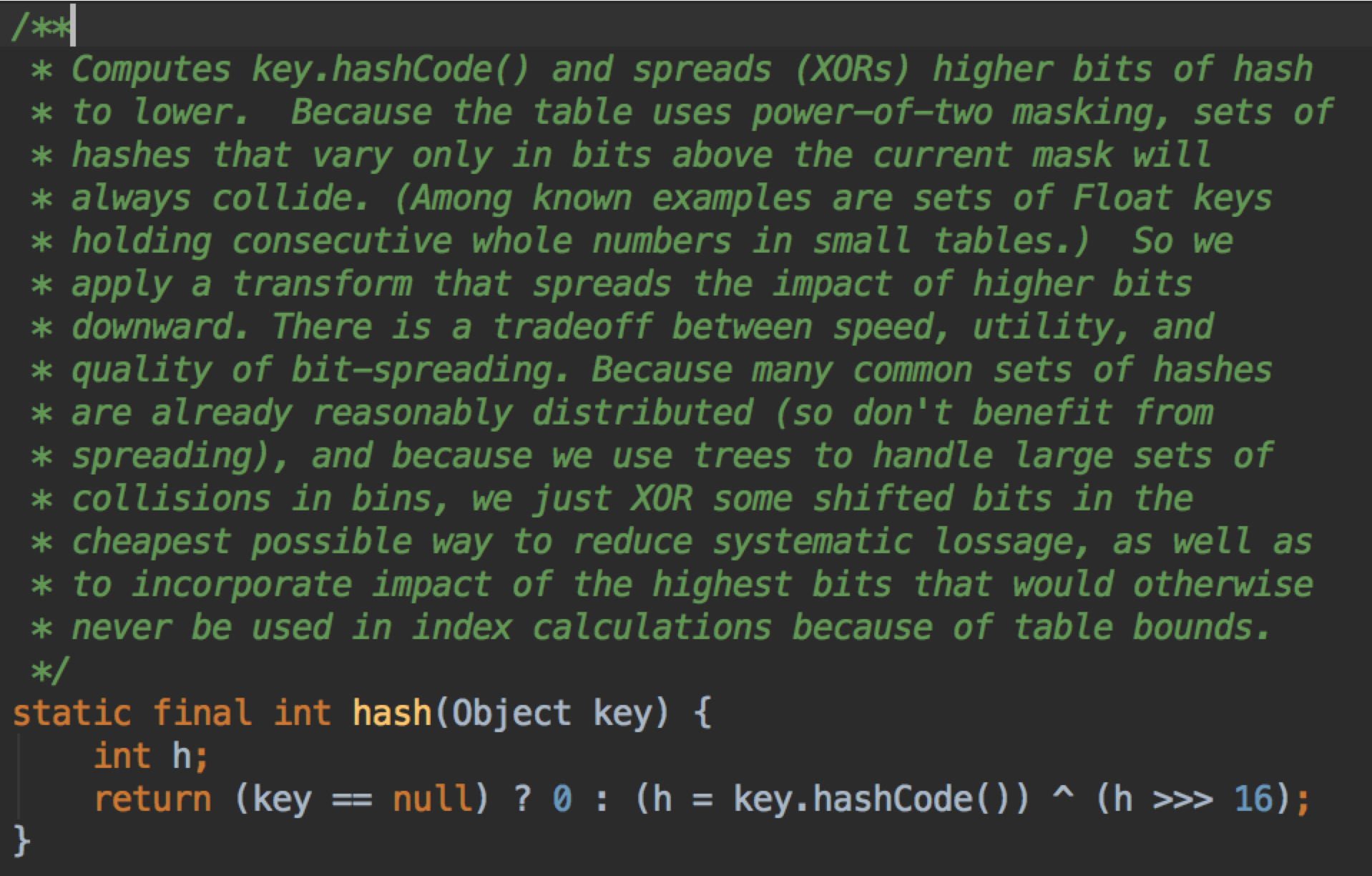
这是JDK1.8优化之后的样子,key.hashCode() 是个 int 即 32位;
h >>> 16 表示无符号右移 16 位,即保留高16位;
(>>> 意思是右移时无论是正数还是负数,高位统一补0;>> 遇到负数时高位是补1的)
然后,用高16位异或低16位,得到新的低16位,得到的结果就是高16位是原来的高16位,低16位是原来高16位和原来低16位的异或结果。
为什么要这样做?我们再看看取出数组下标的方法再说。
定位到 table[] 的下标就是 (length - 1 ) & hash(原来这一行代码在JDK1.7是一个叫做 indexFor 的方法,JDK1.8把这个方法删掉了)。
没错就是通过 & 的操作,通过 & 运算可以获得一个小于 length - 1 的值。size 是保证等于 2 的 N 次方,所以 hash & (size -1 ) 就相当于做取模运算。
那么我们回答一下刚刚的问题:
既然取模会忽略高位,那么在 size 比较小的情况下,取模结果就取决于低位,譬如 241(11110001) 和 1009(1111110001) 这两个 hashcode 对 size 为16(1111) 的取模结果都是 1,但是这两个数还是相差比较大的嘛,我们的本意是希望尽量的分散。
那么 (h = key.hashCode()) ^ (h >>> 16) 的做法就是把高16位加入到低16位去,以此来让低位16位保留高16位的“特征”(高16位是这个 hashcode 的主要特征,这样做法就是可以让低16位也可以表现出这个数的主要特征),同时也加大低16位的随机性。
这样做的目的主要是为了提高运算的速度和 hash 的效率,防止 hash 冲突。
JDK1.7的hash算法由于“不怎么随机”,发生过类似 DOS 的攻击
HASH COLLISION DOS 问题
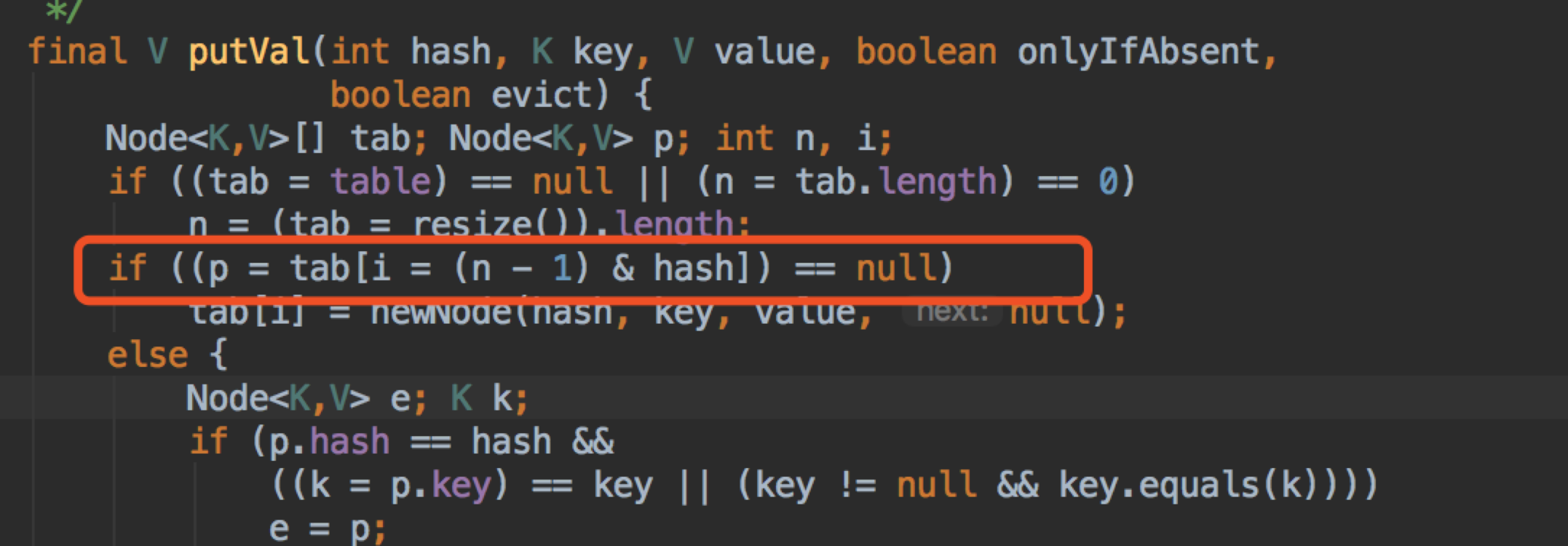
putVal的思路
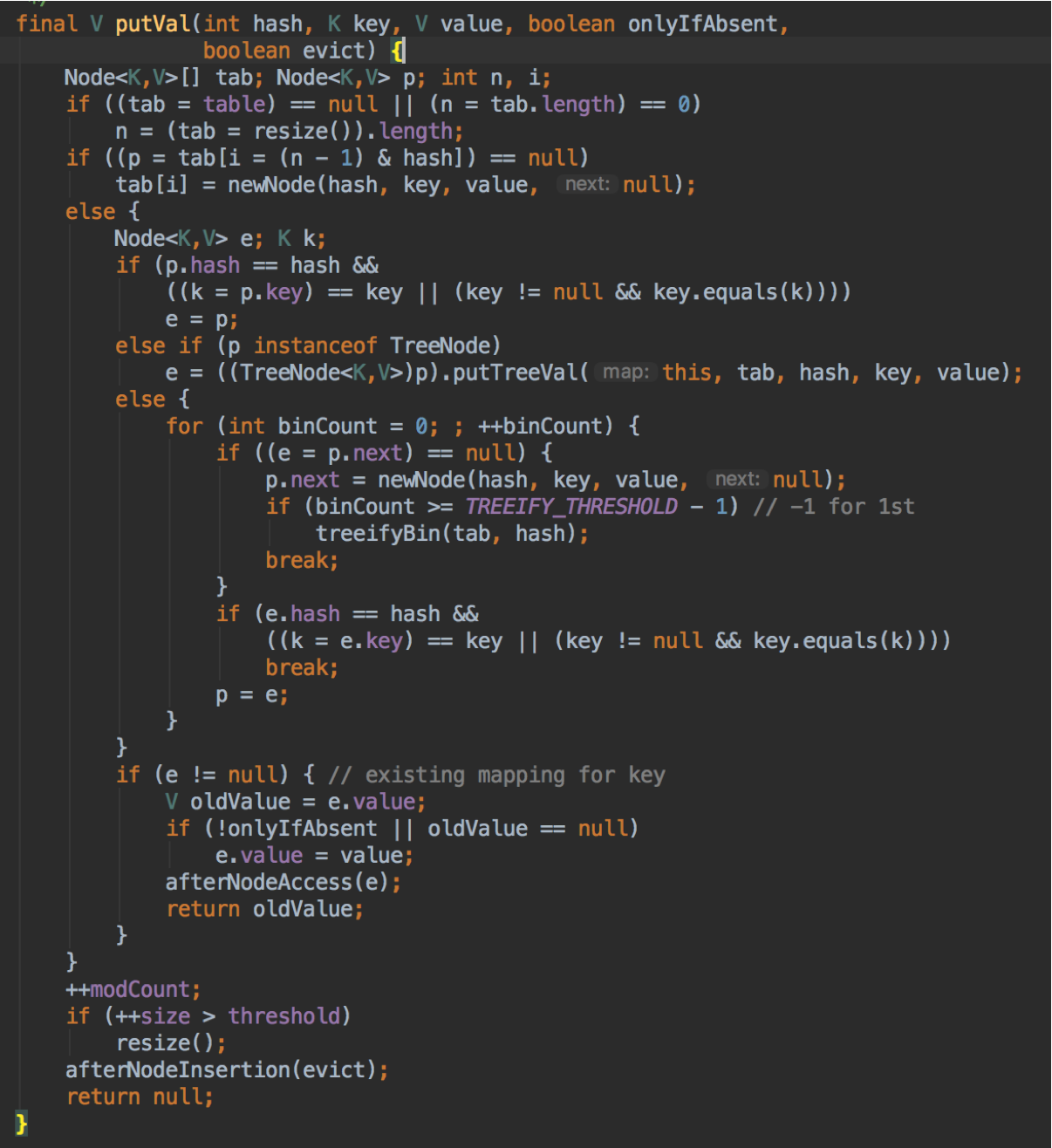
大概思路:
对key的hashCode()做hash,然后再计算index;
如果没碰撞直接放到bucket里;
如果碰撞了,以链表的形式存在buckets后;
如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
如果节点已经存在就替换old value(保证key的唯一性)
如果bucket满了(超过load factor * current capacity),就要resize。
关于threshold和loadFactor
大家都知道 threshold 的作用是当 size 大于 threshold 时就会进行 resize,但是 threshold 的值是多少呢?
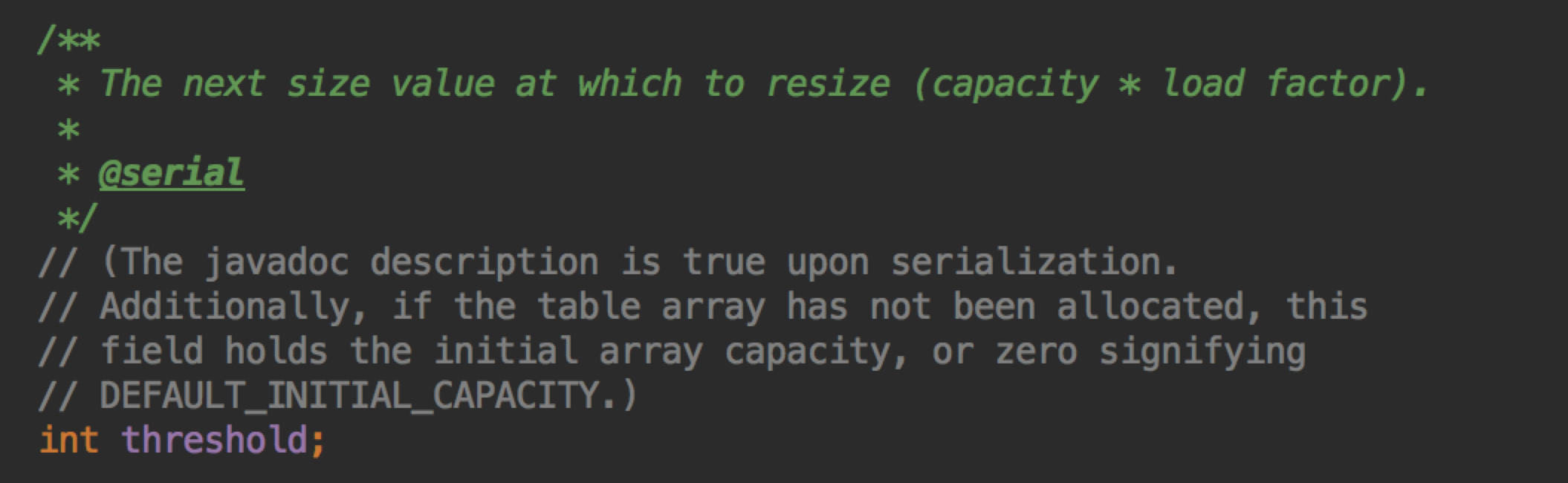
threshold = capacity * load factor
loadFactor 默认为 0.75 是时间和空间上折中考虑。如果太大,虽然会减少空间的占用,但是会增加查询的时间度,因为发生碰撞的几率会提高,从而从 O(1) 退化为链表或者红黑树的查询。
resize后如何保证key的位置
JDK1.8由于 hash 方法的优化,所以 resize 也受到影响。
官方的注释说,经过 rehash 之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
为什么会这样?
我盗一下图

元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

上面的图说的很明白,如果原来的 hashcode 在高1位有值,那么在“取模”的运算中,这个“1”会被保留下来,所以 new index = old index + oldCap,如果高1位是0,结果还是跟原来一样。
这个设计巧妙在于,整体容量扩容了1倍的意义是对每一个 table[i] 都公平的扩容了1倍,而对每个元素是否需要挪到新的 table[i + oldCap]就随机性般的取决于“高1位”是0还是1,在平均的情况下各占50%。
我又盗一个图
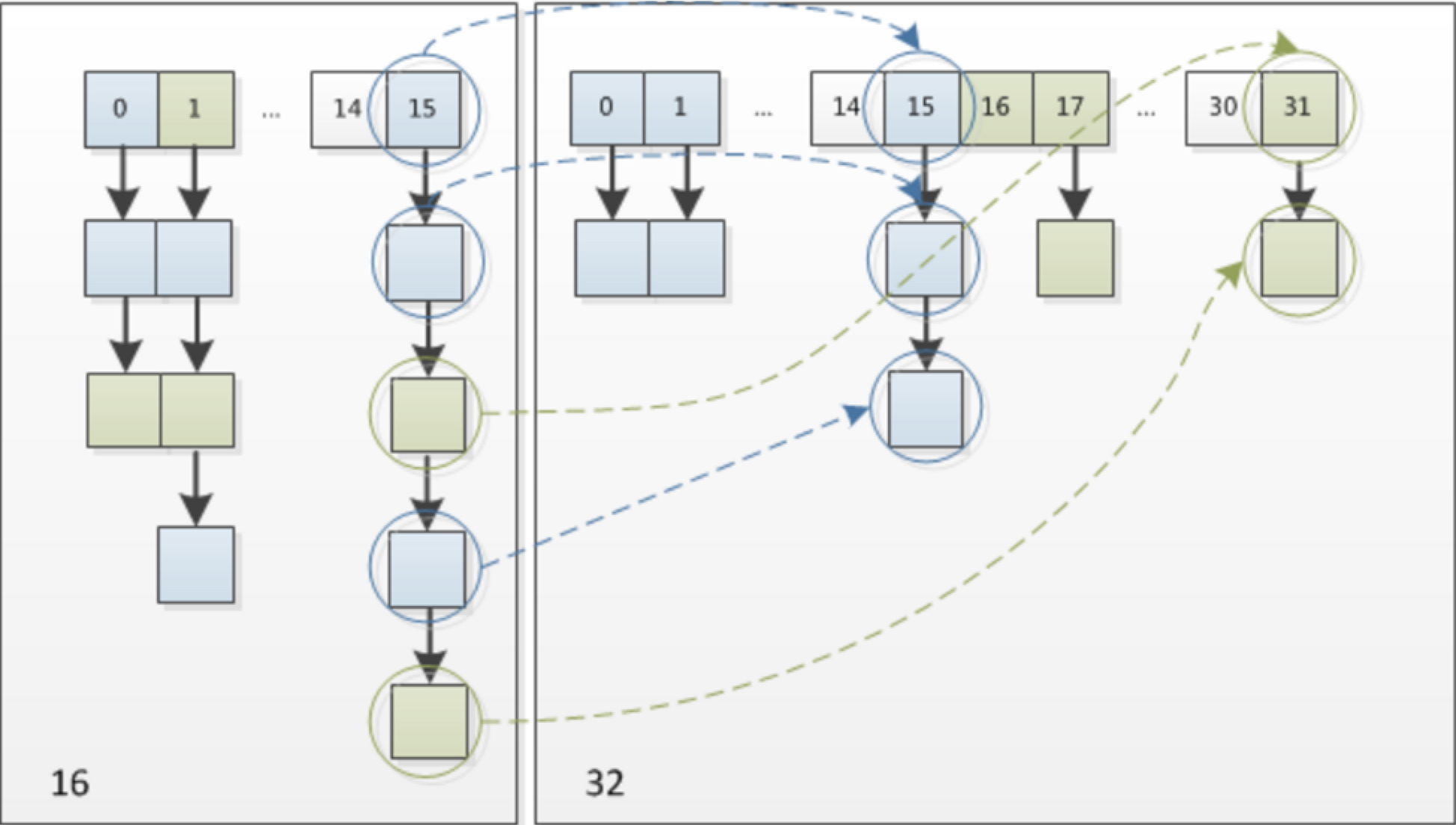
这个图说的很明白,原来在 15 的位置,在 resize 后,蓝色的还是在 15 的位置,绿色就变成在 31 的位置了(31 = 15 + 16)。
还有一点注意就是,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是在JDK1.8不会倒置。
resize在高并发下引发的死循环
这是在JDK1.7之前才会出现的问题,简单来说就是在高并发下,在内部操作时导致链表死循环引用。参考老生常谈,HashMap的死循环
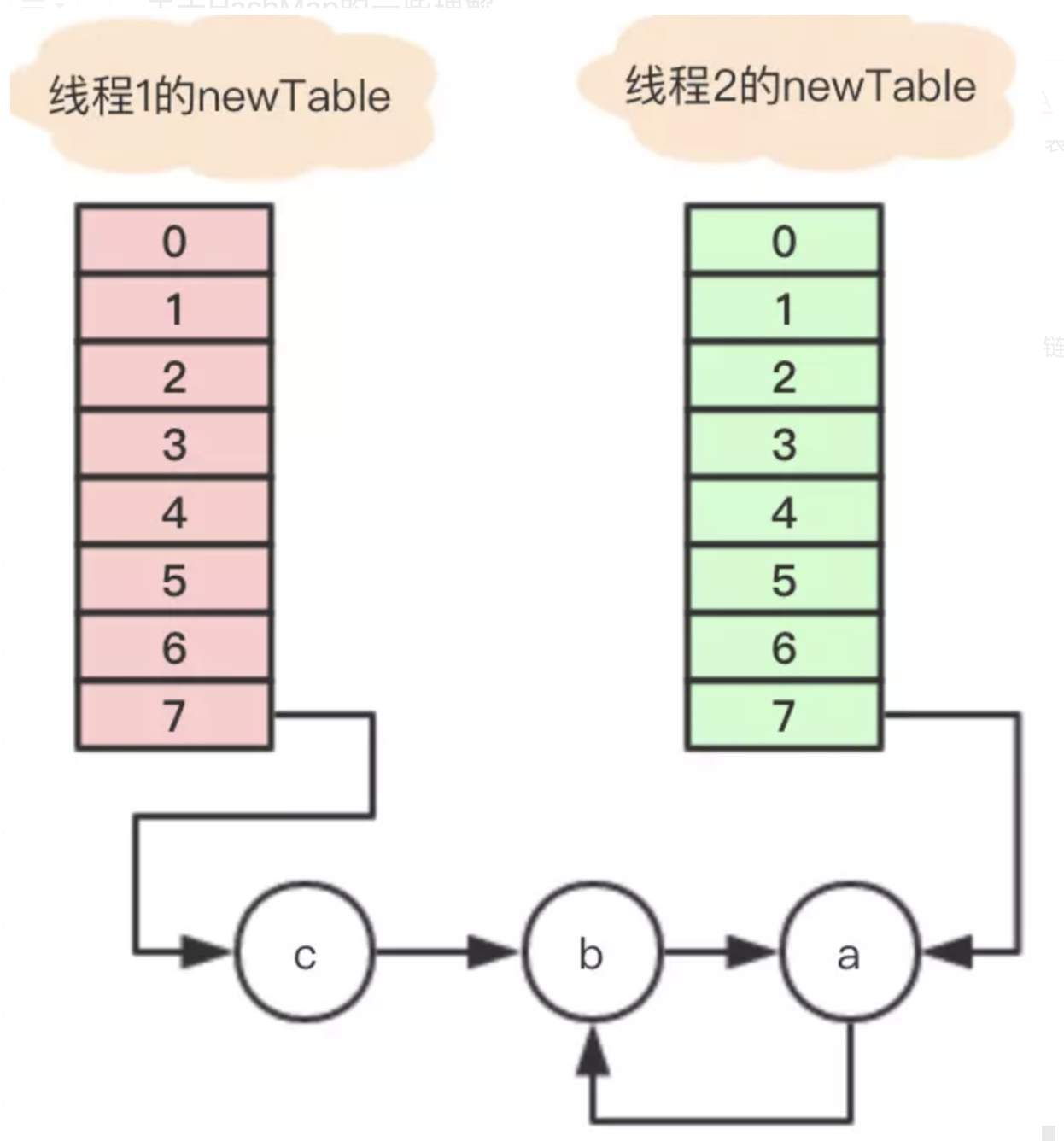
这根本原因是在 rehash 时,链表以倒序进行重新排列。
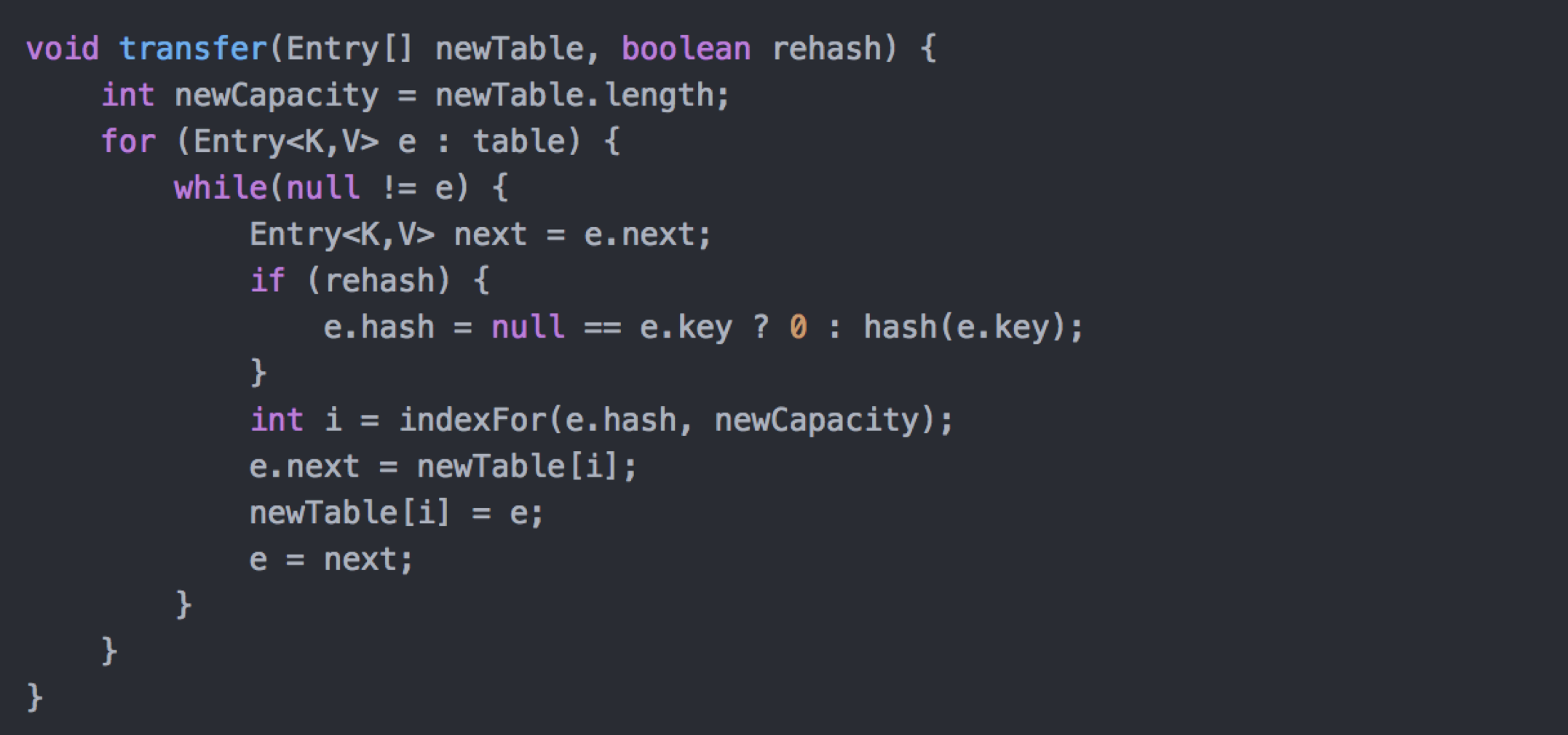
但是在JDK1.8后,这个问题得到了优化
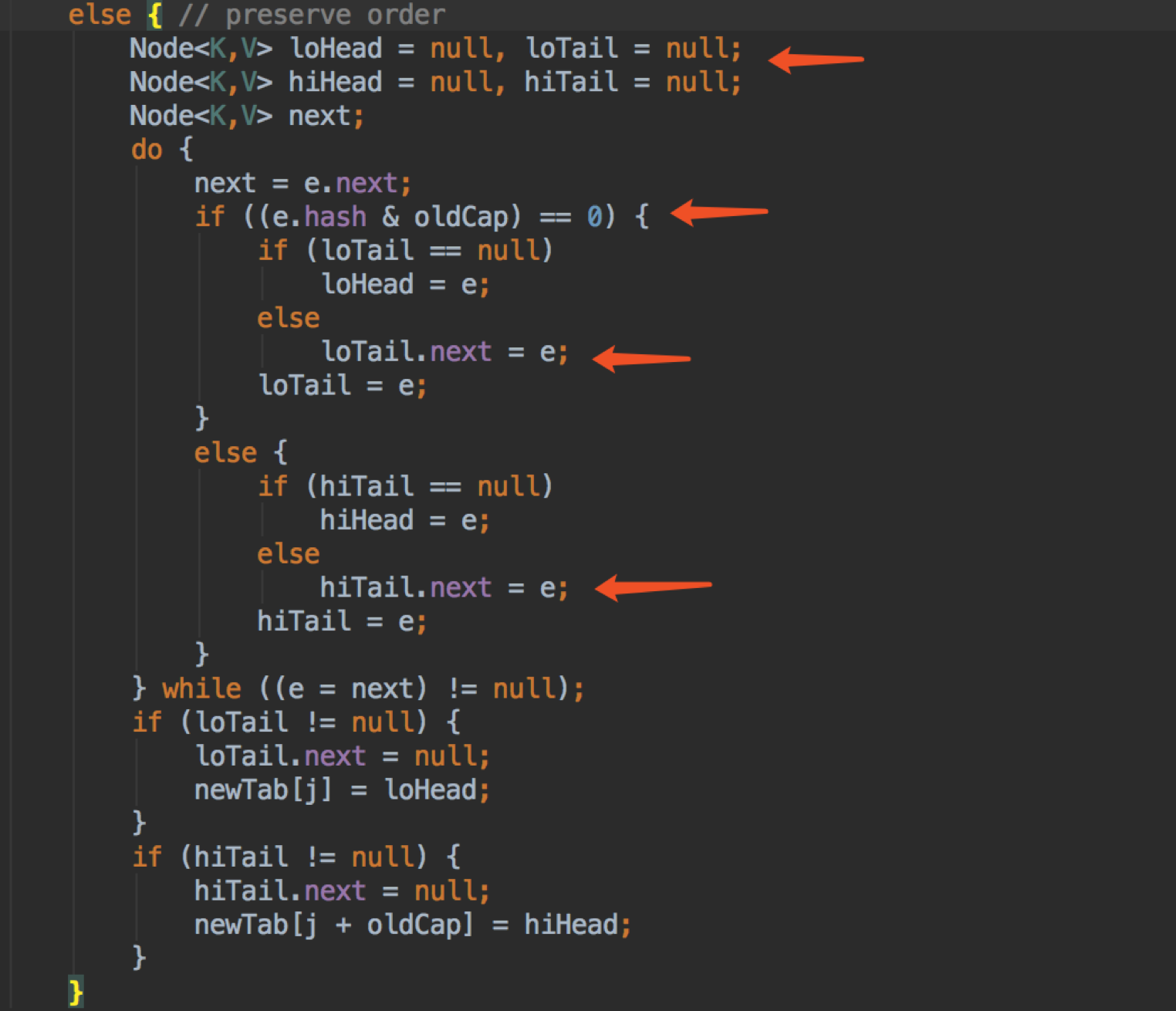
这里的代码需要对应到上面有蓝色和绿色两个链表的图。
loHead 和 loTail 代表蓝色的那个链表,也即“高1位”不为1的 hashcode 的那些节点,它们 resize 后还是放在原来的位置上。
hiHead 和 hiTail 代表绿色的那个链表,也即“高1位”位1的 hashcode 的那些节点,它们 resize 后会放在 oldIndex + oldCap 的位置上。
这里可以看出链表是以原来的顺序排列的,tail 节点不停往后追加,head 没有改变,遍历完之后就让 tab[i] 指向 head 就好了。
JDK1.8 之后不仅解决了死循环的问题(虽然在并发下还有其他问题),而且代码也更加简洁易懂。
为什么TREEIFY_THRESHOLD=8?
我们看看官方的注释
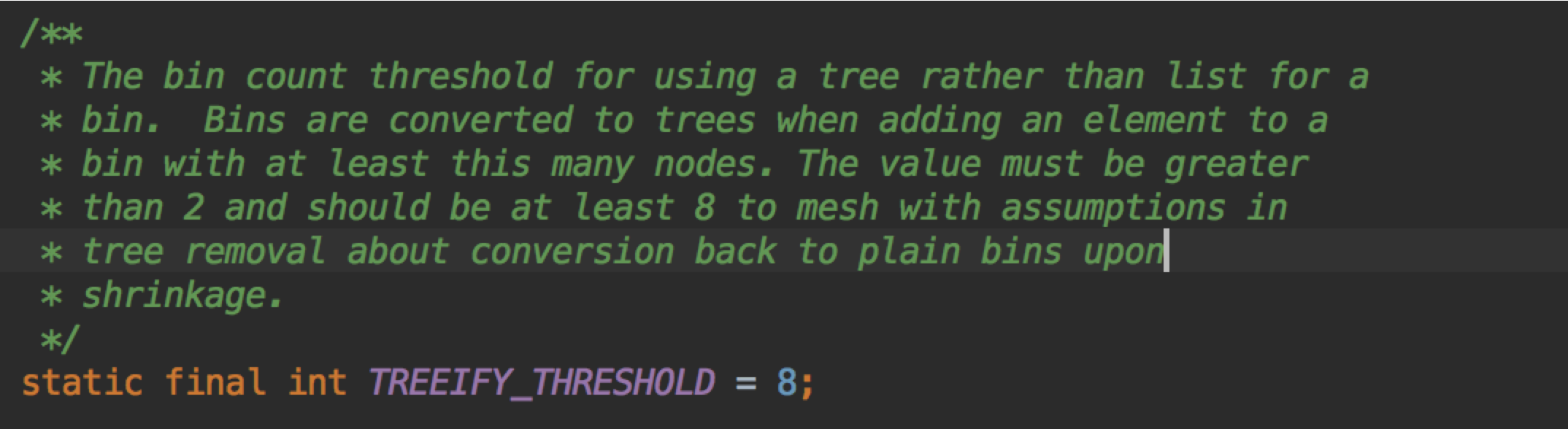
TREEIFY_THRESHOLD 的作用是链表转为红黑树的阈值,这个之前已经说了。
那么为什么是8呢?继续看官方的注释
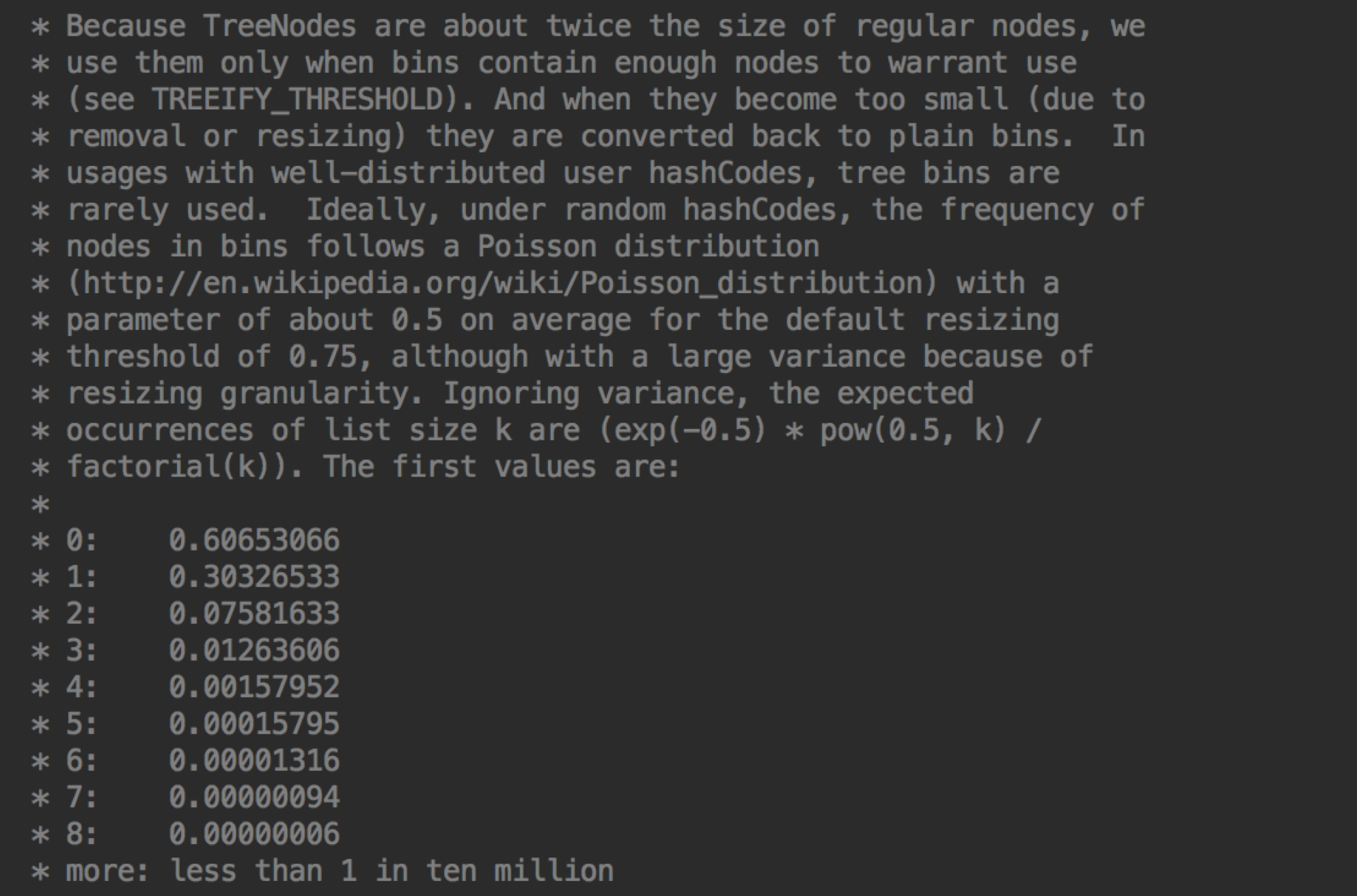
大概意思是如果 hash 很理想,分布就会很平均,tree bins 就会很少用到。
在理想的情况下,节点的分布符合柏松分布(Poisson distribution)。
我们来分析一下,先看看柏松分布的概率函数
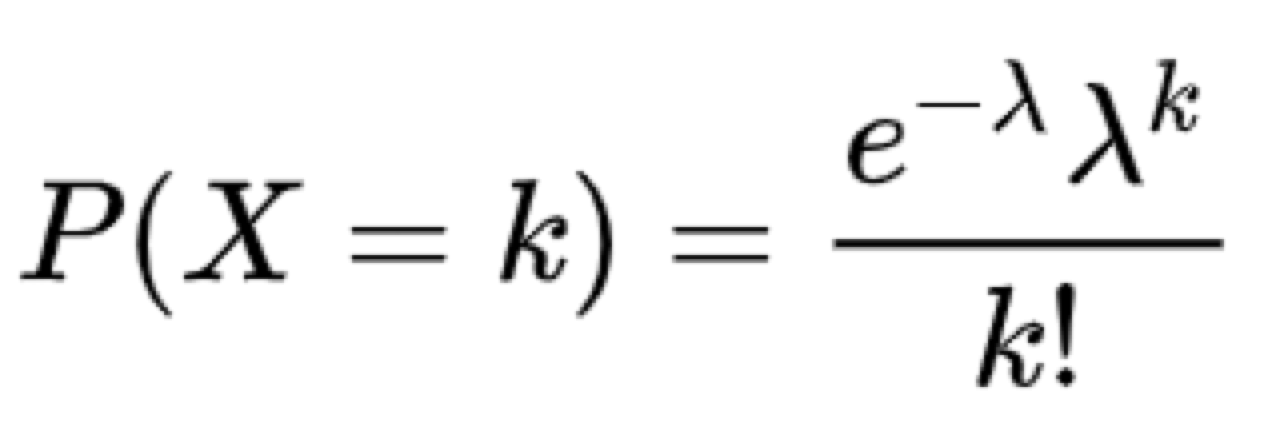
我们假设事件 X=k 为某一个 bucket 有 k 个节点。
柏松分布只有一个参数就是 λ,那么 λ 为多少呢?
官方的说法是
Ideally, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average, given the resizing threshold of 0.75
它说 λ = 0.5,但是我想了大半天都没想明白为什么是 0.5(如果有人知道的话,恳请您告诉我),我觉得有可能它是统计出来的。
我说一下我的想法:
二项分布的极限是柏松分布,我们可以根据二项分布的期望 λ=np 求出 λ(n 是实验的次数,p 是单次的概率)。如果 n 比较大,p 比较小,所以我们才说满足泊松分布的条件。
我们知道如果 hash 很理想,那么分散在每个 bucket 的概率看作一样,p = 1 / s,s 为 bucket 的长度,如果进行了 n 次实验,那么 s = n / 0.75,所以代进去得出 λ = 0.75
于是我们可以根据柏松分布得出事件 X=0,X=1 … 的概率分布
0: 0.4724
1: 0.3543
2: 0.1329
3: 0.0332
4: 0.0062
5: 0.0009
6: 0.0001
可以看出得到的结果跟官方的差不多,X=8 之前的概率累积接近1。
也就是说在某一个 bucket 存在多于 8 个节点的概率极低,这就是 TREEIFY_THRESHOLD = 8 的原因。
允许 null 值的原因
ConcurrentHashmap 和 Hashtable 都是不允许 null 的 key 和 value 的,而 HashMap 允许,这是为什么呢?
这样一对比,就很容易联想到是由于并发问题引起的。
Doug Lea 是这么说的:
The main reason that nulls aren’t allowed in ConcurrentMaps
(ConcurrentHashMaps, ConcurrentSkipListMaps) is that
ambiguities that may be just barely tolerable in non-concurrent
maps can’t be accommodated. The main one is that if
map.get(key) returns null, you can’t detect whether the
key explicitly maps to null vs the key isn’t mapped.
In a non-concurrent map, you can check this via map.contains(key),
but in a concurrent one, the map might have changed between calls.
大概意思是,在并发下,如果 map.get(key) = null,ConcurrentMap 无法判断 key 的 value 为null,还是 key 不存在。
但是 HashMap 只考虑在非并发下运行,可以用 map.contains(key) 来做判断。
大师还说
I personally think that allowing
nulls in Maps (also Sets) is an open invitation for programs
to contain errors that remain undetected until
they break at just the wrong time. (Whether to allow nulls even
in non-concurrent Maps/Sets is one of the few design issues surrounding
Collections that Josh Bloch and I have long disagreed about.)Collections that Josh Bloch and I have long disagreed about.)
Doug Lea 大师也说了,自己对 HashMap 允许 null 也是有争议的。这样做只能等到程序报错才发现错误。
参考资料
https://tech.meituan.com/java_hashmap.html
https://www.jianshu.com/p/281137bdc223