概要
Guava Cache是一款非常优秀本地缓存,使用起来非常灵活,功能也十分强大。Guava Cache说简单点就是一个支持LRU的ConcurrentHashMap,并提供了基于容量,时间和引用的缓存回收方式。
本文详细的介绍了Guava Cache的使用注意事项,即最佳实践,以及作为一个Local Cache的实现原理。
应用及使用
应用场景
- 读取热点数据,以空间换时间,提升时效
- 计数器,例如可以利用基于时间的过期机制作为限流计数
基本使用
Guava Cache提供了非常友好的基于Builder构建者模式的构造器,用户只需要根据需求设置好各种参数即可使用。Guava Cache提供了两种方式创建一个Cache。
CacheLoader
CacheLoader可以理解为一个固定的加载器,在创建Cache时指定,然后简单地重写V load(K key) throws Exception方法,就可以达到当检索不存在的时候,会自动的加载数据的。例子代码如下:
1 | //创建一个LoadingCache,并可以进行一些简单的缓存配置 |
Callable
在上面的build方法中是可以不用创建CacheLoader的,不管有没有CacheLoader,都是支持Callable的。Callable在get时可以指定,效果跟CacheLoader一样,区别就是两者定义的时间点不一样,Callable更加灵活,可以理解为Callable是对CacheLoader的扩展。例子代码如下:
1 |
|
其他用法
显式插入:
支持loadingCache.put(key, value)方法直接覆盖key的值。
显式失效:
支持loadingCache.invalidate(key) 或 loadingCache.invalidateAll() 方法,手动使缓存失效。
缓存失效机制
Guava Cache有一套十分优秀的缓存失效机制,这里主要介绍的是基于时间的失效回收。
缓存失效的目的是让缓存进行重新加载,即刷新,使调用者可以正常访问获取到最新的数据,而不至于返回null或者直接访问DB。
从上面的例子中我们知道与失效/缓存刷新相关配置有 expireAfterWrite / expireAfterAccess、refreshAfterWrite 还有 CacheLoader的reload方法。
一般用法
expireAfterWrite/expireAfterAccess
使用背景
如果对缓存设置过期时间,在高并发下同时执行get操作,而此时缓存值已过期了,如果没有保护措施,则会导致大量线程同时调用生成缓存值的方法,比如从数据库读取,对数据库造成压力,这也就是我们常说的“缓存击穿”。
做法
而Guava cache则对此种情况有一定控制。当大量线程用相同的key获取缓存值时,只会有一个线程进入load方法,而其他线程则等待,直到缓存值被生成。这样也就避免了缓存击穿的危险。这两个配置的区别前者记录写入时间,后者记录写入或访问时间,内部分别用writeQueue和accessQueue维护。
PS: 但是在高并发下,这样还是会阻塞大量线程。
refreshAfterWrite
使用背景
使用 expireAfterWrite 会导致其他线程阻塞。
做法
更新线程调用load方法更新该缓存,其他请求线程返回该缓存的旧值。
异步刷新
使用背景
单个key并发下,使用refreshAfterWrite,虽然不会阻塞了,但是如果恰巧同时多个key同时过期,还是会给数据库造成压力,这就是我们所说的“缓存雪崩”。
做法
这时就要用到异步刷新,将刷新缓存值的任务交给后台线程,所有的用户请求线程均返回旧的缓存值。
方法是覆盖CacheLoader的reload方法,使用线程池去异步加载数据
PS:只有重写了 reload 方法才有“异步加载”的效果。默认的 reload 方法就是同步去执行 load 方法。
总结
大家都应该对各个失效/刷新机制有一定的理解,清楚在各个场景可以使用哪个配置,简单总结一下:
expireAfterWrite 是允许一个线程进去load方法,其他线程阻塞等待。
refreshAfterWrite 是允许一个线程进去load方法,其他线程返回旧的值。
在上一点基础上做成异步,即回源线程不是请求线程。异步刷新是用线程异步加载数据,期间所有请求返回旧的缓存值。
实现原理
数据结构
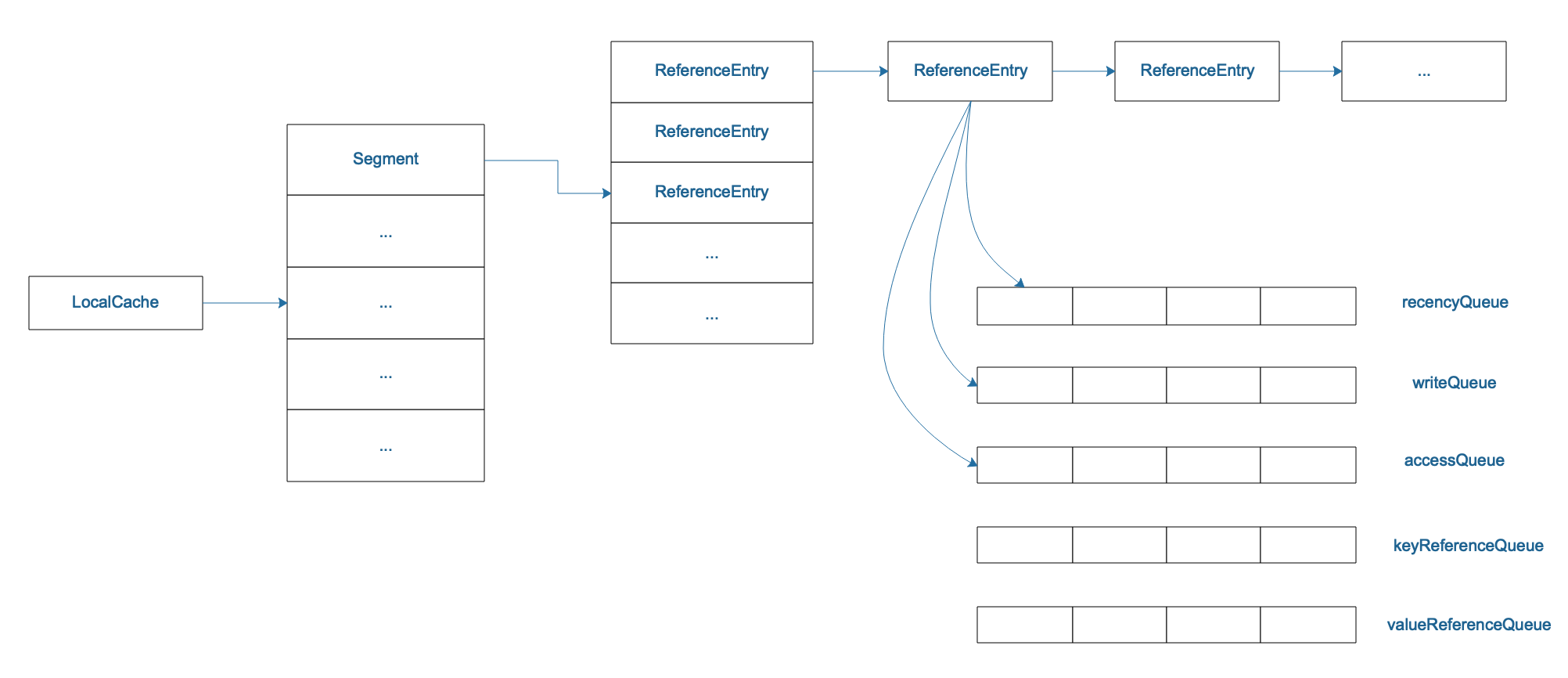
Guava Cache的数据结构跟JDK1.7的ConcurrentHashMap类似,如下图所示:
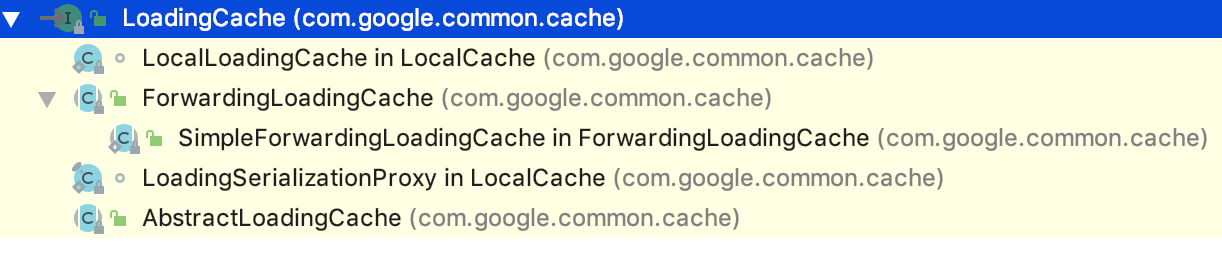
LoadingCache
LoadingCache即是我们API Builder返回的类型,类继承图如下:
LocalCache
LoadingCache这些类表示获取Cache的方式,可以有多种方式,但是它们的方法最终调用到LocalCache的方法,LocalCache是Guava Cache的核心类。看看LocalCache的定义:
1 | class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V> |
说明Guava Cache本质就是一个Map。
LocalCache的重要属性:
1 | //Map的数组 |
Segment
从上面可以看出LocalCache这个Map就是维护一个Segment数组。Segment是一个ReentrantLock
1 | static class Segment<K, V> extends ReentrantLock |
看看Segment的重要属性:
1 | //LocalCache |
ReferenceEntry
ReferenceEntry就是一个Entry的引用,有几种引用类型:
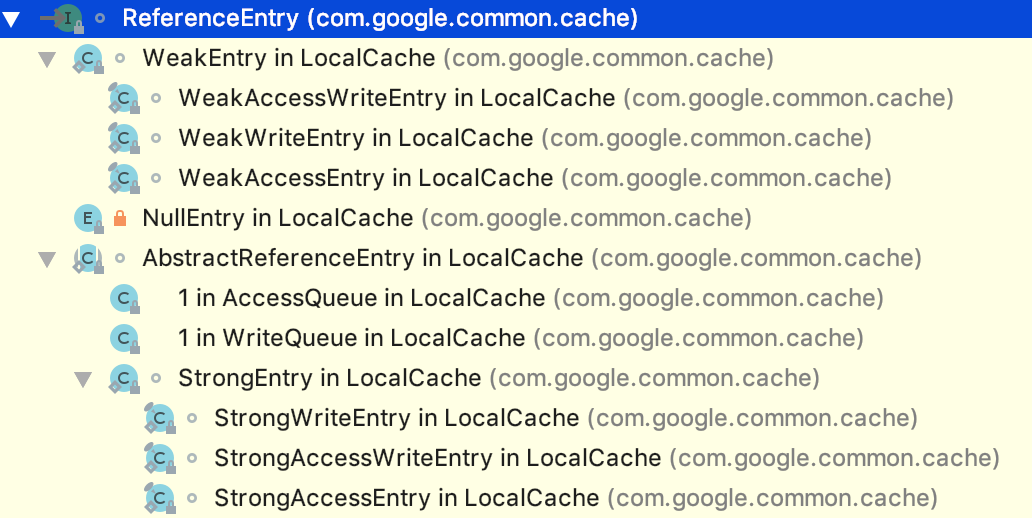
我们拿StrongEntry为例,看看有哪些属性:
1 | final K key; |
源码分析
当我们了解了Guava Cache的结构后,那么进行源码分析就会简单很多。
本文只对put和get这两个重点操作来进行源码分析,其他源码如果读者感兴趣请自行阅读。
以下源码基于guava-26.0-jre版本。
get
get主流程
我们从LoadingCache的get(key)方法入手:
1 | //LocalLoadingCache的get方法,直接调用LocalCache |
LocalCache:
1 | V getOrLoad(K key) throws ExecutionException { |
Segment:
1 | V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { |
scheduleRefresh
从get的流程得知,如果entry还没过期,则会进入此方法,尝试去刷新数据。
1 | V scheduleRefresh( |
lockedGetOrLoad
如果之前没有写入过数据 || 数据已经过期 || 数据不是在加载中,则会调用lockedGetOrLoad
1 | V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { |
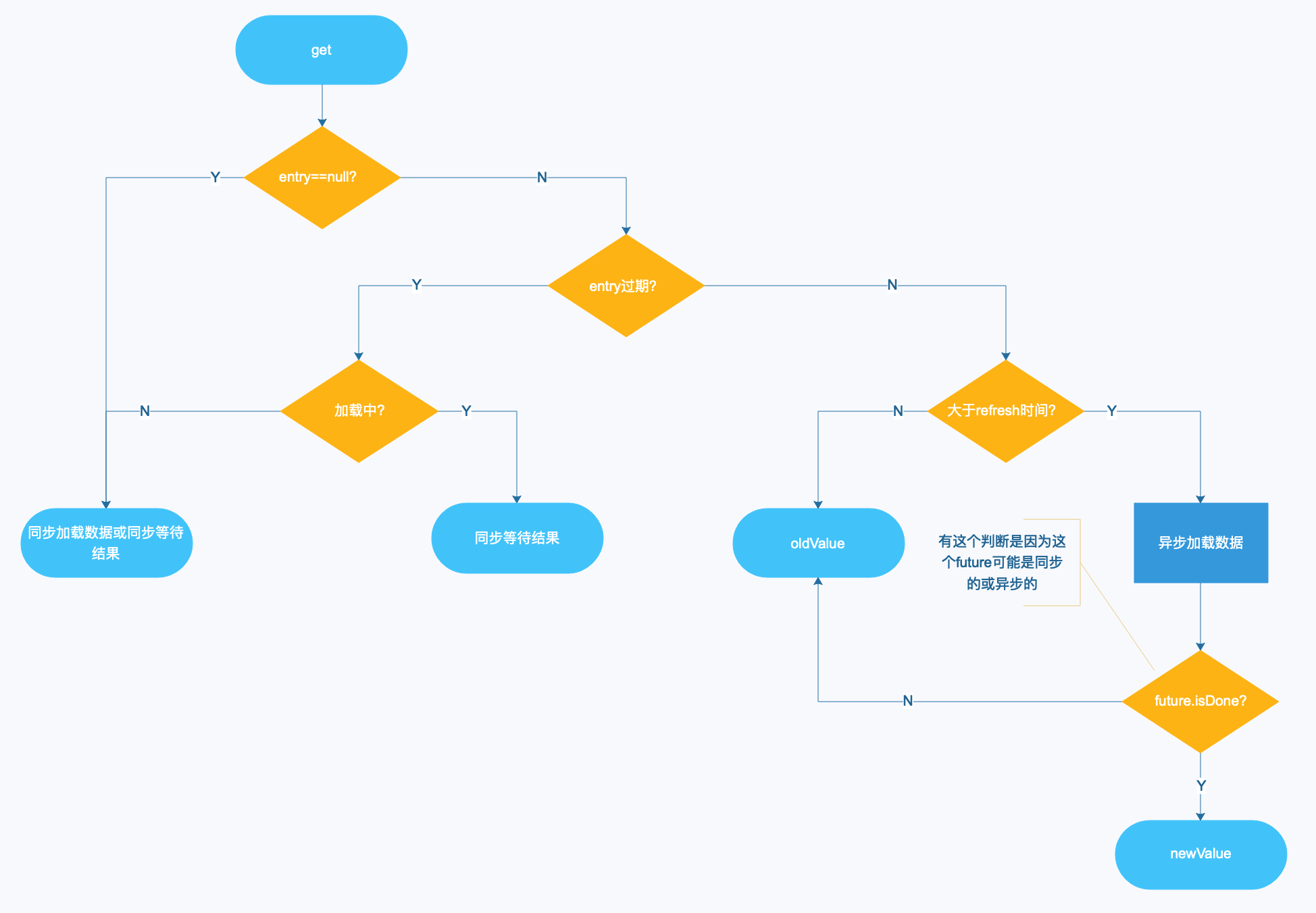
流程图
通过分析get的主流程代码,我们来画一下流程图:
put
看懂了get的代码后,put的代码就显得很简单了。
Segment的put方法:
1 | V put(K key, int hash, V value, boolean onlyIfAbsent) { |
put的流程相对get来说没有那么复杂。
最佳实践
关于最佳实践,在上面的“缓存失效机制”中得知,看来使用refreshAfterWrite是一个不错的选择,但是从上面get的源码分析和流程图看出,或者了解Guava Cache都知道,Guava Cache是没有定时器或额外的线程去做清理或加载操作的,都是通过get来触发的,目的是降低复杂性和减少对系统的资源消耗。
那么只使用refreshAfterWrite或配置不当的话,会带来一个问题:如果一个key很长时间没有访问,这时来一个请求的话会返回旧值,这个好像不是很符合我们的预想,在并发下返回旧值是为了不阻塞,但是在这个场景下,感觉有足够的时间和资源让我们去刷新数据。
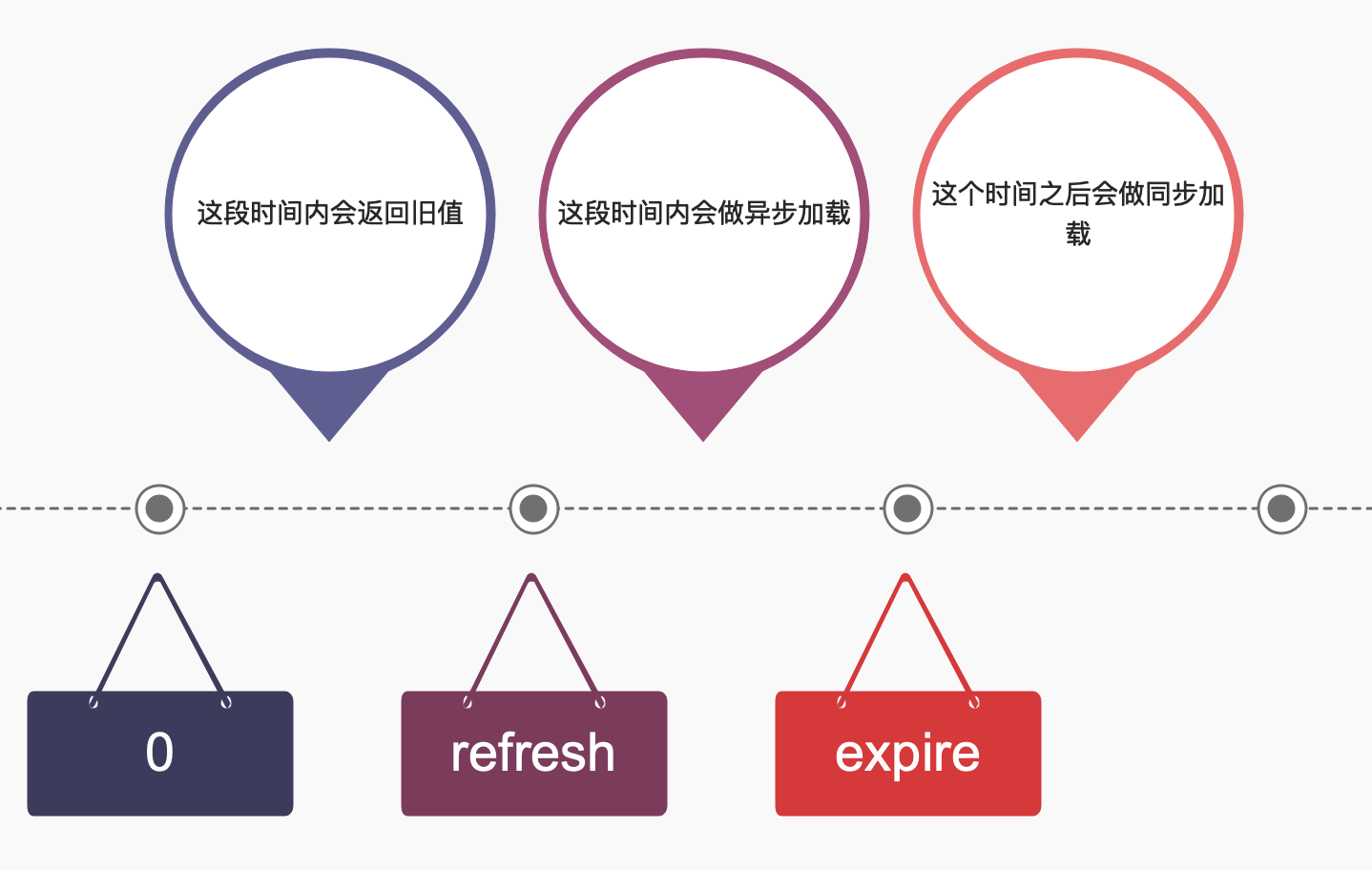
结合get的流程图,在get的时候,是先判断过期,再判断refresh,即如果过期了会优先调用 load 方法(阻塞其他线程),在不过期情况下且过了refresh时间才去做 reload (异步加载,同时返回旧值),所以推荐的设置是 refresh < expire,这个设置还可以解决一个场景就是,如果长时间没有访问缓存,可以保证 expire 后可以取到最新的值,而不是因为 refresh 取到旧值。
用一张时间轴图简单表示:
总结
Guava Cache是一个很优秀的本地缓存工具,缓存的作用不多说,一个简单易用,功能强大的工具会使你在开发中事倍功半。但是跟所有的工具一样,你要在了解其内部原理、机制的情况下,才能发挥其最大的功效,才能适用到你的业务场景中。
本文通过对Guava Cache的使用、核心机制的讲解、核心源代码的分析以及最佳实践的说明,相信你会对Guava Cache有更进一步的了解。