概要
Java对Excel的操作一般都是用POI,但是数据量大的话可能会导致频繁的FGC或OOM,这篇文章跟大家说下如果避免踩POI的坑,以及分别对于xls和xlsx文件怎么优化大批量数据的导入和导出。
一次线上问题
这是一次线上的问题,因为一个大数据量的Excel导出功能,而导致服务器频繁FGC,具体如图所示
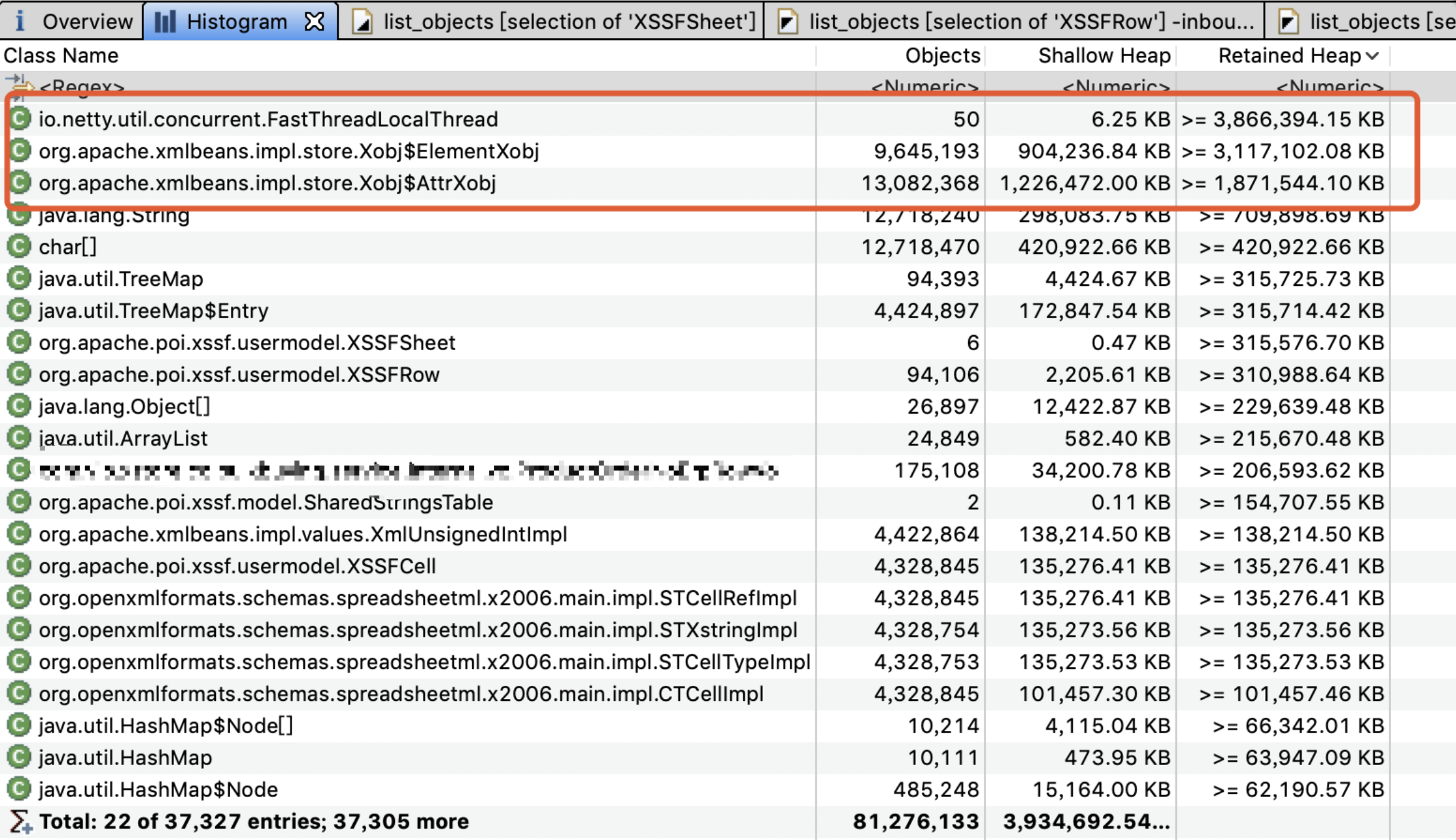
可以看出POI的对象以及相关的XML对象占用了绝大部分的内存消耗,频繁FGC说明这些对象一直存活,没有被回收。
原因是由于导出的数据比较大量,大概有10w行 * 50列,由于后台直接用XSSFWorkbook导出,在导出结束前内存有大量的Row,Cell,Style等,以及基于XLSX底层存储的XML对象没有被释放。
Excel的存储格式
下面的优化内容涉及Excel的底层存储格式,所以要先跟大家讲一下。
XLS
03版的XLS采用的是一种名为BIFF8(Binary-Interchange-File-Format),基于OLE2规范的二进制文件格式。大概就是一种结构很复杂的二进制文件,具体细节我也不是很清楚,大家也没必要去了解它,已经被淘汰了。想了解的话可以看看Excel XLS文件格式
XLSX
07版的XLSX则是采用OOXML(Office Open Xml)的格式存储数据。简单来说就是一堆xml文件用zip打包之后文件。这个对于大家来说就熟悉了,把xlsx文件后缀名改为zip后,再解压出来就可以看到文件结构,对每个文件以及里面内容的意思可以看看Excel 2007(一) - XML存储
打开sheet1.xml,可以看到是描述第一个sheet的内容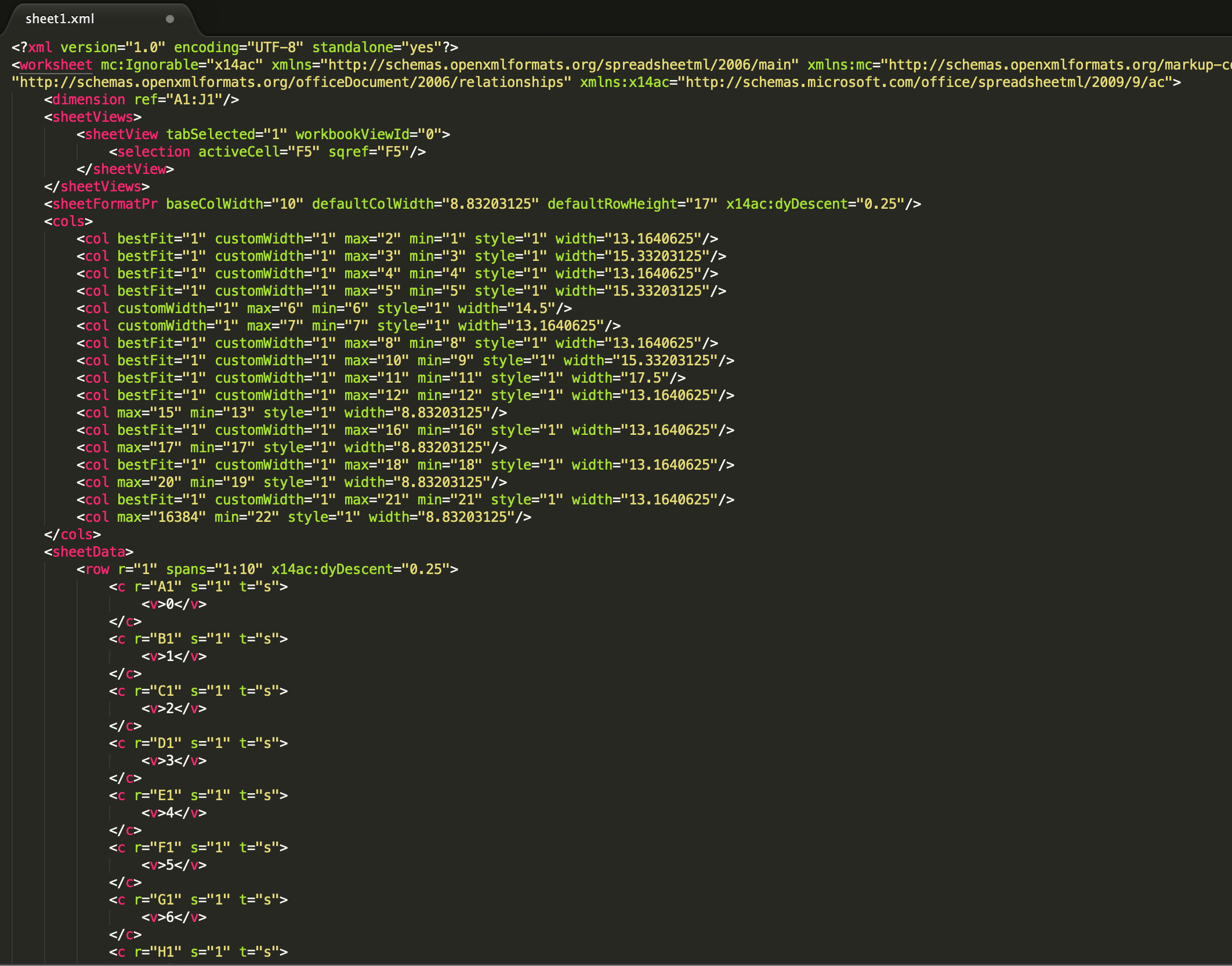
导出优化
事例源码基于POI3.17版本
XLSX
由于xlsx底层使用xml存储,占用内存会比较大,官方也意识到这个问题,在3.8版本之后,提供了SXSSFWorkbook来优化写性能。官方说明
使用
SXSSFWorkbook使用起来特别的简单,只需要改一行代码就OK了。
原来你的代码可能是长这样的
1 | Workbook workbook = new XSSFWorkbook(inputStream); |
那么你只需要改成这样子,就可以用上SXSSFWorkbook了
1 | Workbook workbook = new SXSSFWorkbook(new XSSFWorkbook(inputStream)); |
原理
其原理是可以定义一个window size(默认100),生成Excel期间只在内存维持window size那么多的行数Row,超时window size时会把之前行Row写到一个临时文件并且remove释放掉,这样就可以达到释放内存的效果。
SXSSFSheet在创建Row时会判断并刷盘、释放超过window size的Row。
1 |
|
我们再看看刷盘的具体操作
SXSSFSheet在创建的时候,都会创建一个SheetDataWriter,刷盘动作正是由这个类完成的
看下SheetDataWriter的初始化
1 | public SheetDataWriter() throws IOException { |
POI就是把超过window size的Row刷到临时文件里,然后再把临时文件转为正常的xlsx文件格式输出。
我们看看刷盘时写了什么,SheetDataWriter的writeRow方法
1 | public void writeRow(int rownum, SXSSFRow row) throws IOException { |
可以看到临时文件里内容跟xlsx的文件格式是保持一致的。
测试
本地测试使用SXSSFWorkbook导出30w行 * 10列内存使用情况
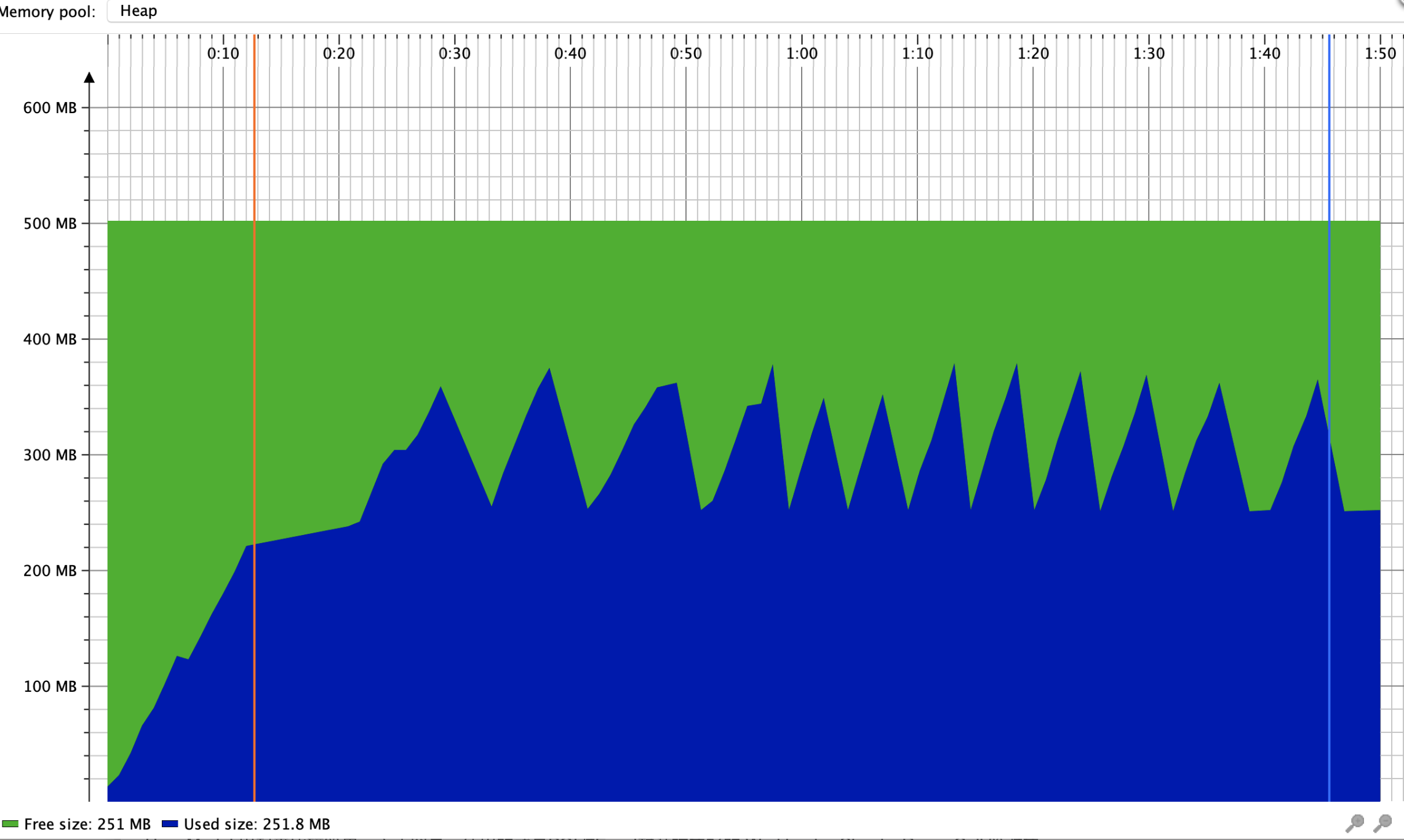
可以看出内存有被回收的情况,比较平稳。
XLS
POI没有像XLSX那样对XLS的写做出性能的优化,原因是:
- 官方认为XLS的不像XLSX那样占内存
- XLS一个Sheet最多也只能有65535行数据
导入优化
POI对导入分为3种模式,用户模式User Model,事件模式Event Model,还有Event User Model。
- 用户模式(User Model)就类似于dom方式的解析,是一种high level api,给人快速、方便开发用的。缺点是一次性将文件读入内存,构建一颗Dom树。并且在POI对Excel的抽象中,每一行,每一个单元格都是一个对象。当文件大,数据量多的时候对内存的占用可想而知。
用户模式就是类似用 WorkbookFactory.create(inputStream),poi 会把整个文件一次性解析,生成全部的Sheet,Row,Cell以及对象,如果导入文件数据量大的话,也很可能会导致OOM。
本地测试用户模式读取XLSX文件,数据量10w行 * 50列,内存使用如下
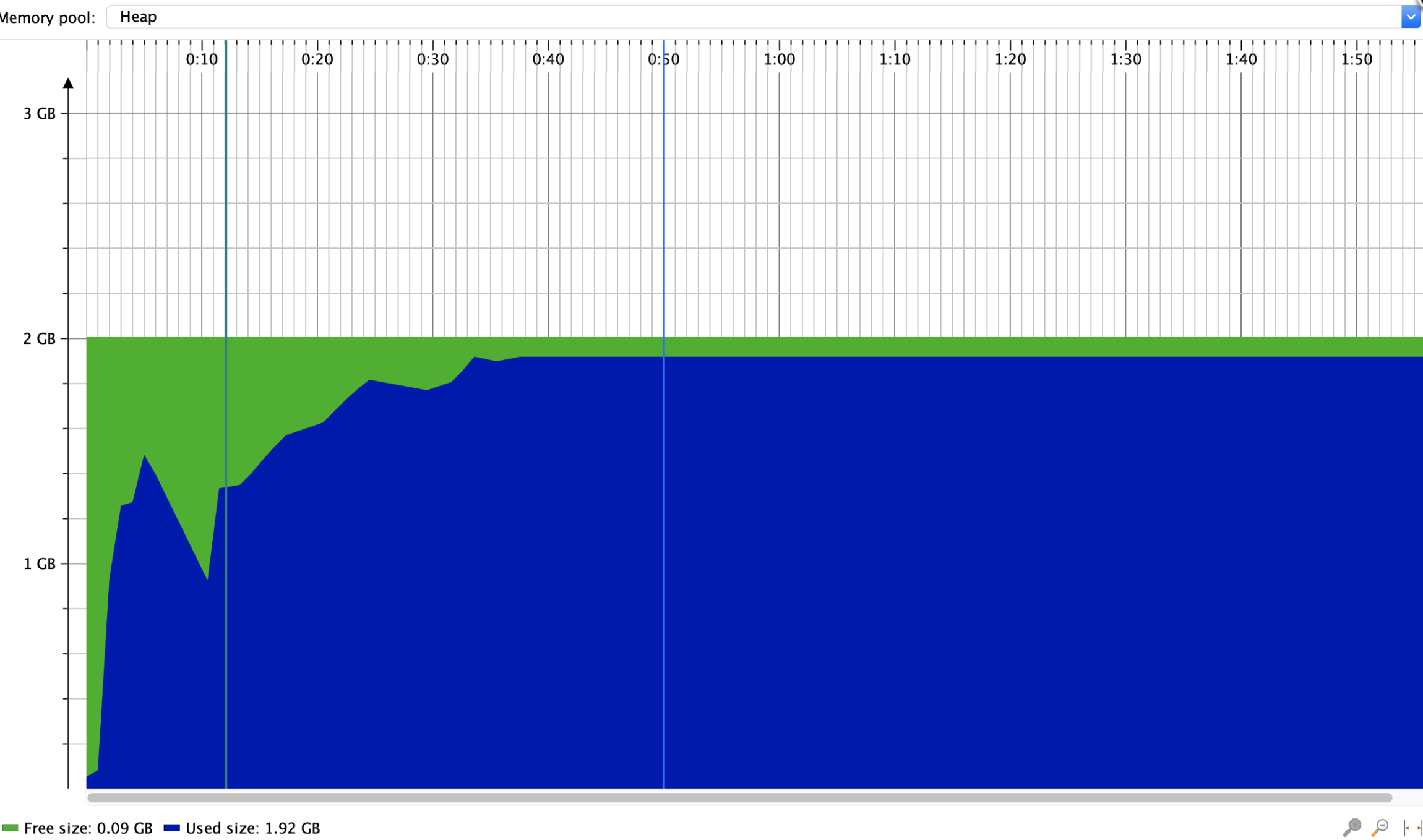
事件模式(Event Model)就是SAX解析。Event Model使用的方式是边读取边解析,并且不会将这些数据封装成Row,Cell这样的对象。而都只是普通的数字或者是字符串。并且这些解析出来的对象是不需要一直驻留在内存中,而是解析完使用后就可以回收。所以相比于User Model,Event Model更节省内存,效率也更。但是作为代价,相比User Model功能更少,门槛也要高一些。我们需要去学习Excel存储数据的各个Xml中每个标签,标签中的属性的含义,然后对解析代码进行设计。
User Event Model也是采用流式解析,但是不同于Event Model,POI基于Event Model为我们封装了一层。我们不再面对Element的事件编程,而是面向StartRow,EndRow,Cell等事件编程。而提供的数据,也不再像之前是原始数据,而是全部格式化好,方便开发者开箱即用。大大简化了我们的开发效率。
XLSX
POI对XLSX支持Event Model和Event User Model
XLSX的Event Model
使用
最直接,权威就是参考官网例子
简单来说就是需要继承DefaultHandler,覆盖其startElement,endElement方法。然后方法里获取你想要的数据。
原理
DefaultHandler相信熟悉的人都知道,这是JDK自带的对XML的SAX解析用到处理类,POI在进行SAX解析时,把读取到每个XML的元素时则会回调这两个方法,然后我们就可以获取到想用的数据了。
我们回忆一下上面说到的XLSX存储格式中sheet存储数据的格式。
再看看官方例子中的解析过程
1 |
|
可以看出你需要对XLSX的XML格式清楚,才能获取到你想要的东西。
XLSX的Event User Model
使用
官方例子
简单来说就是继承XSSFSheetXMLHandler.SheetContentsHandler,覆盖其startRow,endRow,cell,endSheet 等方法。POI每开始读行,结束读行,读取一个cell,结束读取一个sheet时回调的方法。从方法名上看Event User Model有更好的用户体验。
原理
其实Event User Model也是 Event Model的封装,在XSSFSheetXMLHandler(其实也是一个DefaultHandler来的)中持有一个SheetContentsHandler,在其startElement,endElement方法中会调用SheetContentsHandler的startRow,endRow,cell,endSheet等方法。
我们看看XSSFSheetXMLHandler的startElement和endElement方法
1 | public void startElement(String uri, String localName, String qName, |
1 |
|
代码有点多,
- 一是为了展示一下XSSFSheetXMLHandler解析XML的过程,大家可以粗略看看
- 二是可以看出Event User Model也是Event Model的封装
测试
本地测试使用Event User Model读取XLSX文件,数据量10w行 * 50列
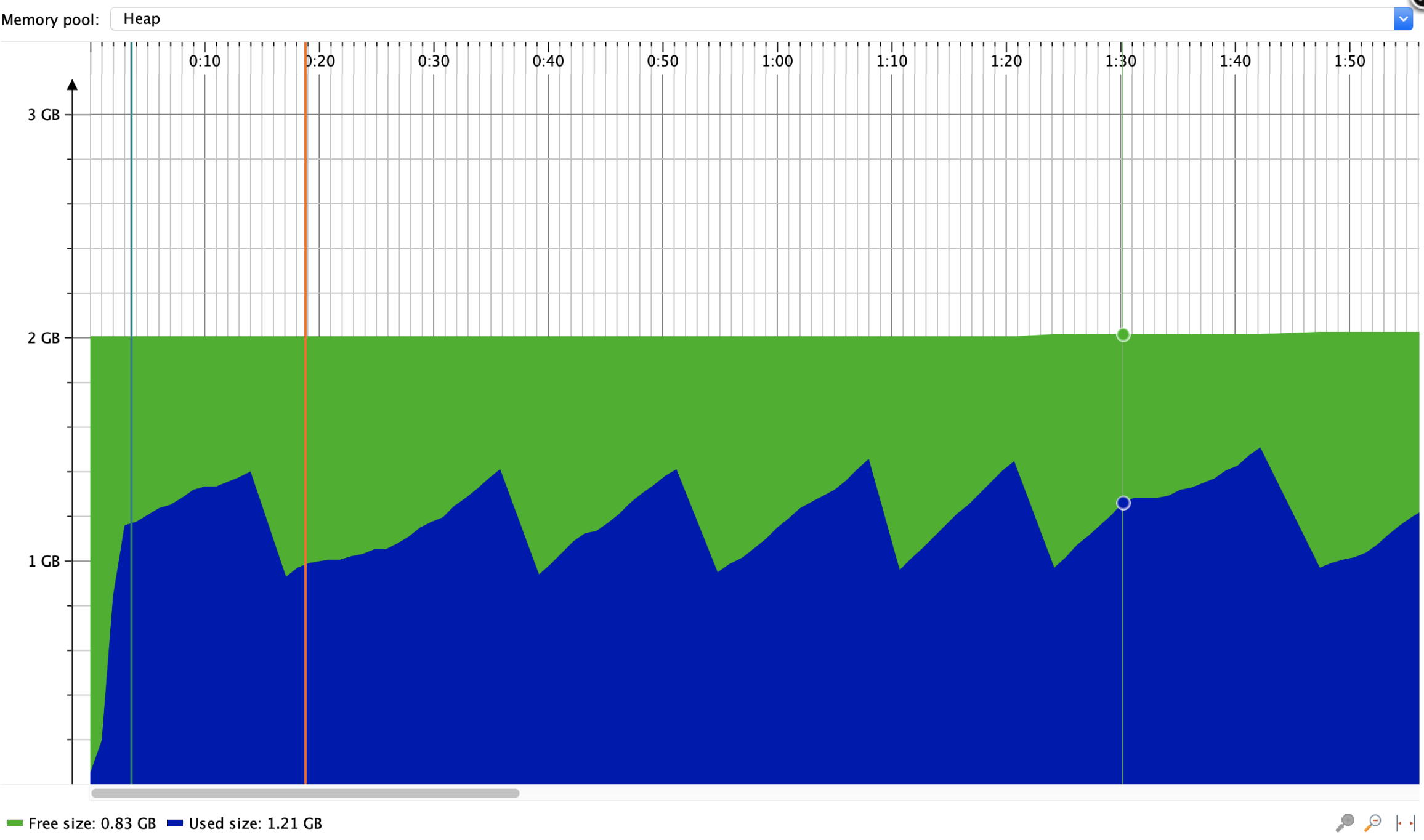
可以看出内存有回收的情况,比User Model好多了。
XLS
POI对XLS支持Event Model
使用
需要继承HSSFListener,覆盖processRecord 方法,POI每读取到一个单元格的数据则会回调次方法。
原理
这里涉及BIFF8格式以及POI对其的封装,大家可以了解一下(因为其格式比较复杂,我也不是很清楚)
总结
POI优化了对XLSX的大批量写,以及支持对XLS和XLSX的SAX读,我们在实际开发时需要根据业务量来选择正确的处理,不然可能会导致OOM。希望这篇文章能给大家启发。另外阿里开源了一个easyexcel,其实做的事情也差不多,大家可以看下。
参考资料
https://www.jianshu.com/p/6d6772f339cb
https://poi.apache.org/components/spreadsheet/how-to.html