概要
ScheduledThreadPoolExecutor 是实现任务调度好工具,它的特点是提供了线程池。
ScheduledThreadPoolExecutor原理
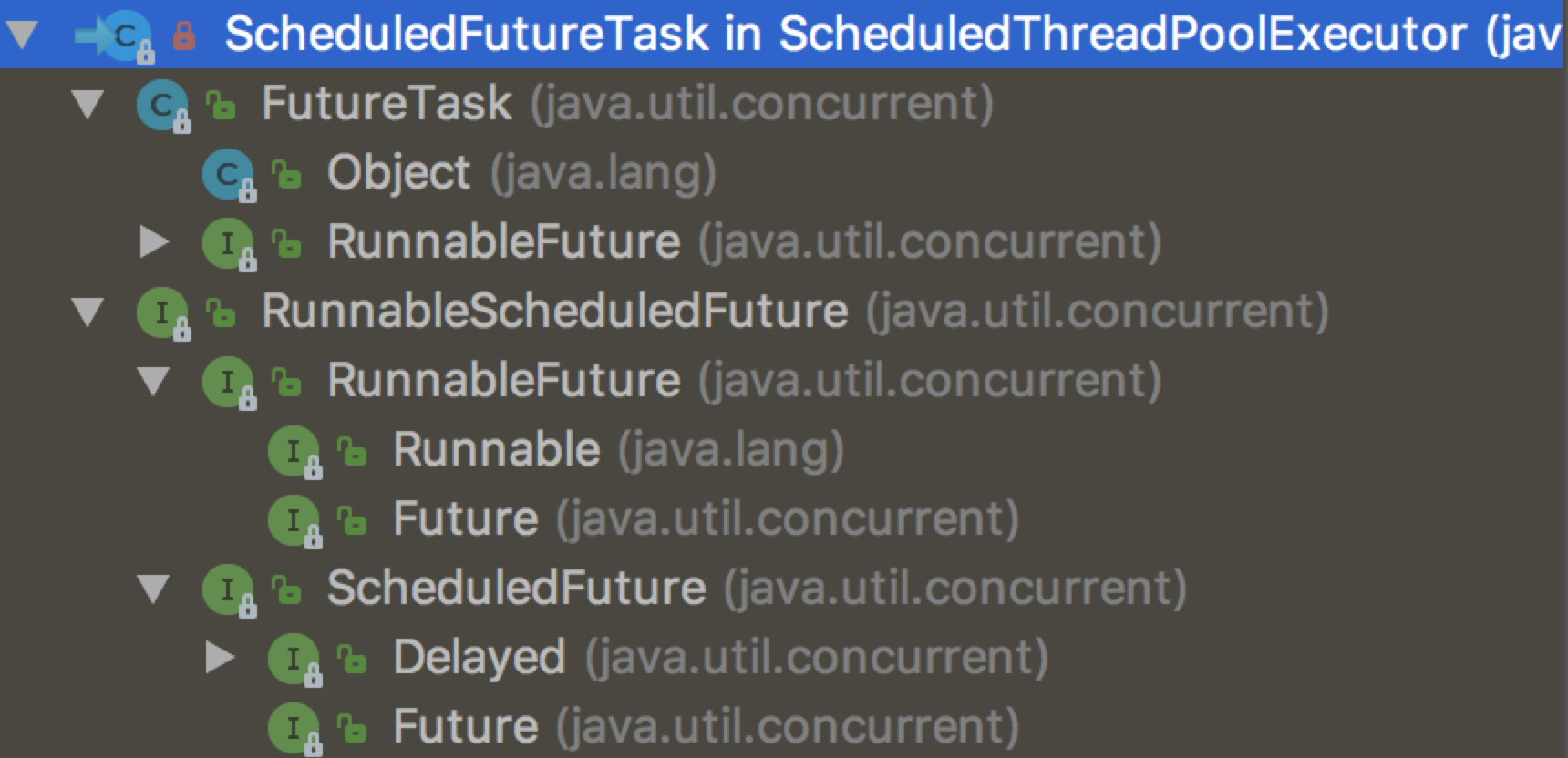
相关类继承关系
首先我们看看 ScheduledThreadPoolExecutor 是什么
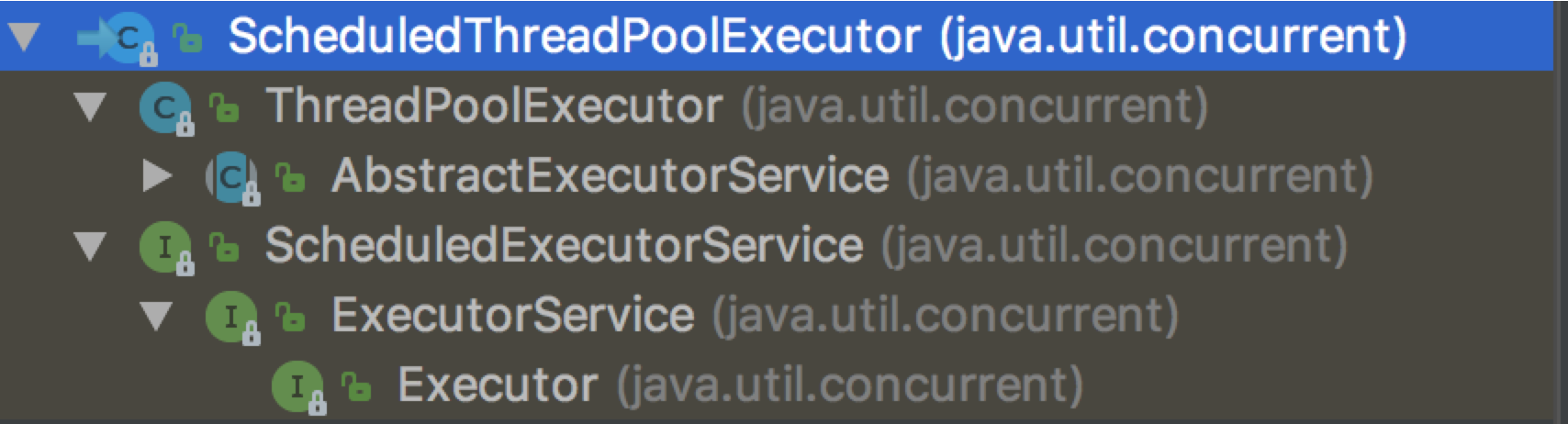
可以看出它是一个 ThreadPoolExecutor,还继承了 ScheduledExecutorService,这个接口定义了诸如 schedule,scheduleAtFixedRate,scheduleWithFixedDelay 等方法。
ScheduledThreadPoolExecutor的创建
先看看构造函数
直接调用 super 的构造方法,即 ThreadPoolExecutor 的,只不过 maximumPoolSize 写死了是 Integer.MAX_VALUE,keepAliveTime 是 0,workQueue 是 DelayedWorkQueue(这个是 ScheduledThreadPoolExecutor 的专用内部 queue,等下会讲到)。
为什么 maximumPoolSize = Integer.MAX_VALUE ?
我看到网上有的说法是,如果对线程数做了限制,就会对定时任务的调度产生延时(假设任务太多,线程忙不过来),这种说法听上去挺合理的,但是是不正确的。可能 ScheduledThreadPoolExecutor 从一开始设计就没有说要严格准时的执行定时任务,所以压根儿就没有考虑这个问题。通过源码发现,maximumPoolSize 是根本没起作用的,线程的数量不会大于 corePoolSize。为什么 maximumPoolSize 没用?是因为 ScheduledThreadPoolExecutor 的 queue 是无界的(每次达到上限会增长50%,跟 DelayQueue 也即 PriorityQueue 一样;如果对这个答案不明白,你可能需要看看 ThreadPoolExecutor )。为什么要用无界 queue ?我猜想是 queue 里面的 task 是延迟或周期性的,会长期驻留,对队列的长度有要求,如果公开给调用者设置或者给一个固定的值,都不合适,会产生问题,所以干脆无界。
还有另外一个原因,设置了 maximumPoolSize 且有效,如果此时 wc > corePoolSize,且队列头的任务 delay 很大,那么在高并发的情况下,会不断有 worker 新建和销毁,造成性能问题,甚至 GC。
为什么 keepAliveTime = 0 ?
一般情况下 maximumPoolSize 不起作用,那么 keepAliveTime 也是不起作用的。
但是也可以通过 allowCoreThreadTimeOut 令到 keepAliveTime 生效(通过调用 allowCoreThreadTimeOut(true) 方法设置),但是这个 keepAliveTime 确实不好设置,试想如果 keepAliveTime 小于队列头的 delay,那么这个线程就会被回收掉,然后在下次又创建一个新的线程,这不是很多余吗,所以干脆 keepAliveTime = 0。
定时任务的执行
schedule方法
ScheduledThreadPoolExecutor 覆盖了 AbstractExecutorService 的 submit 方法,submit 也是直接调用 schedule 方法,我们一般使用也是调用 schedule,我们看看 schedule
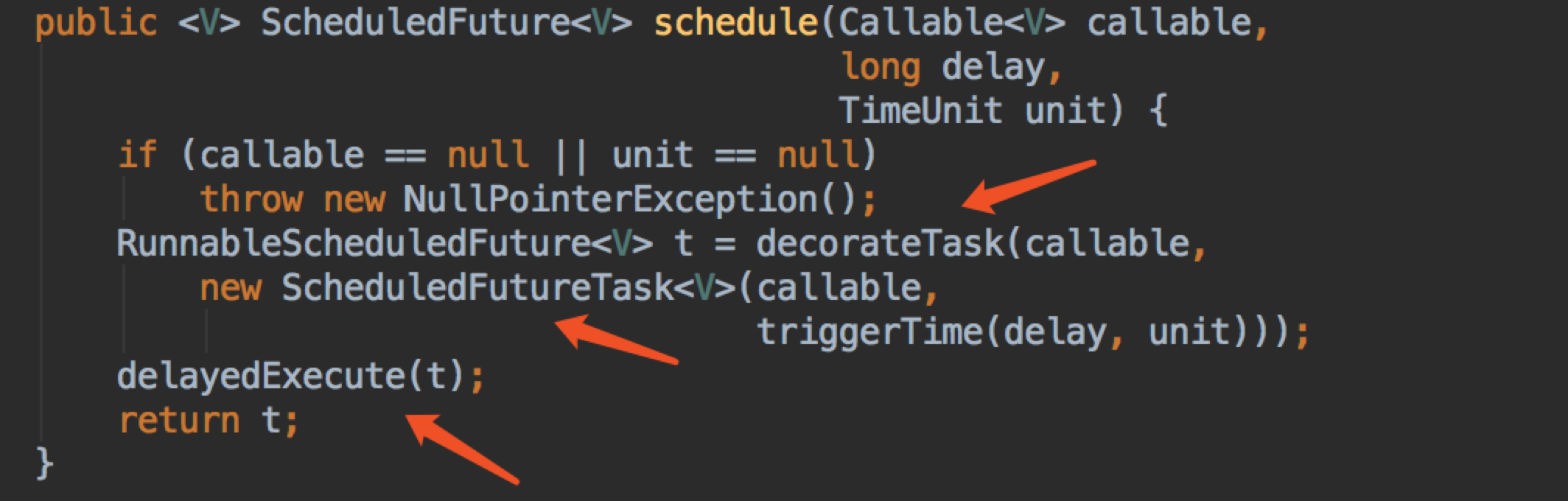
scheduleWithFixedDelay 和 scheduleAtFixedRate 都是类似的,只有一个参数的区别,所以我一起讲
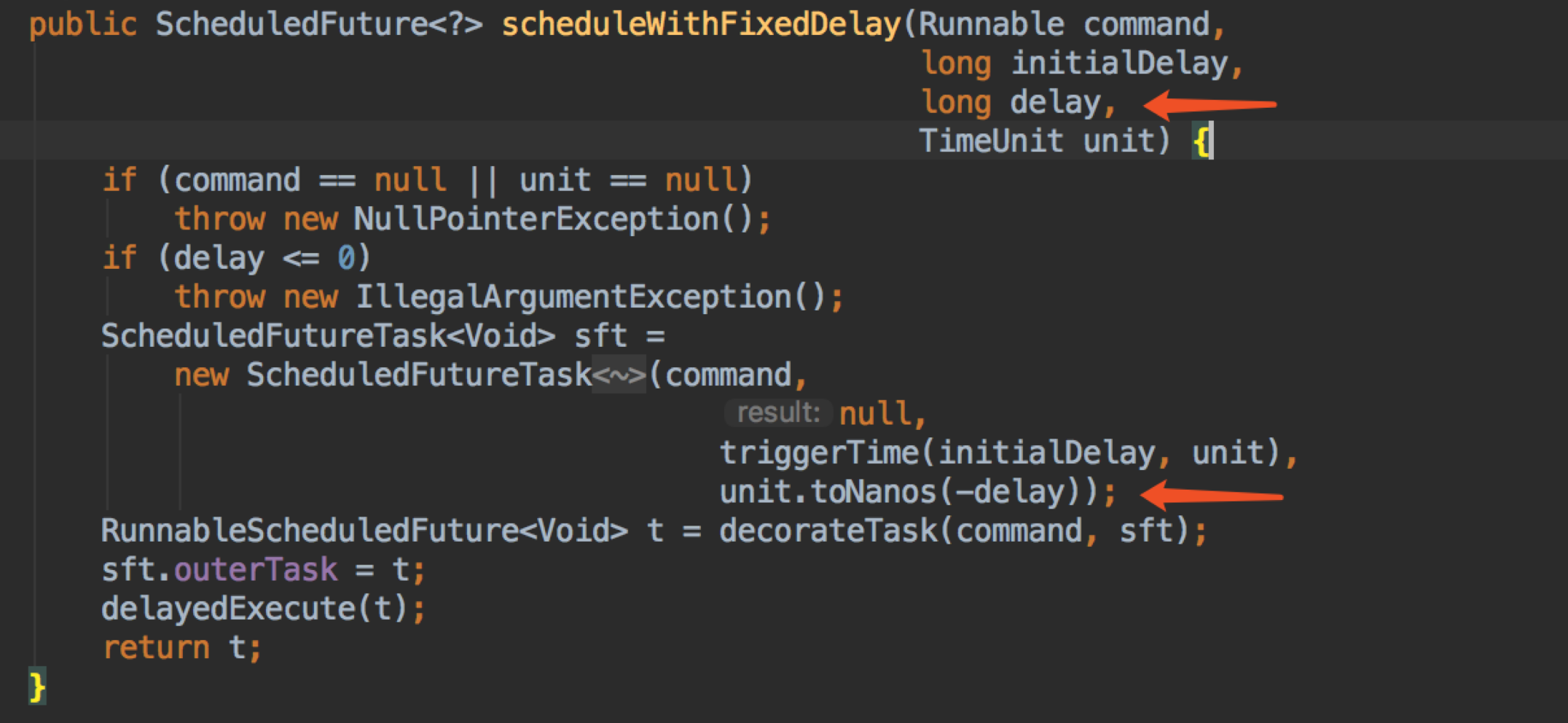
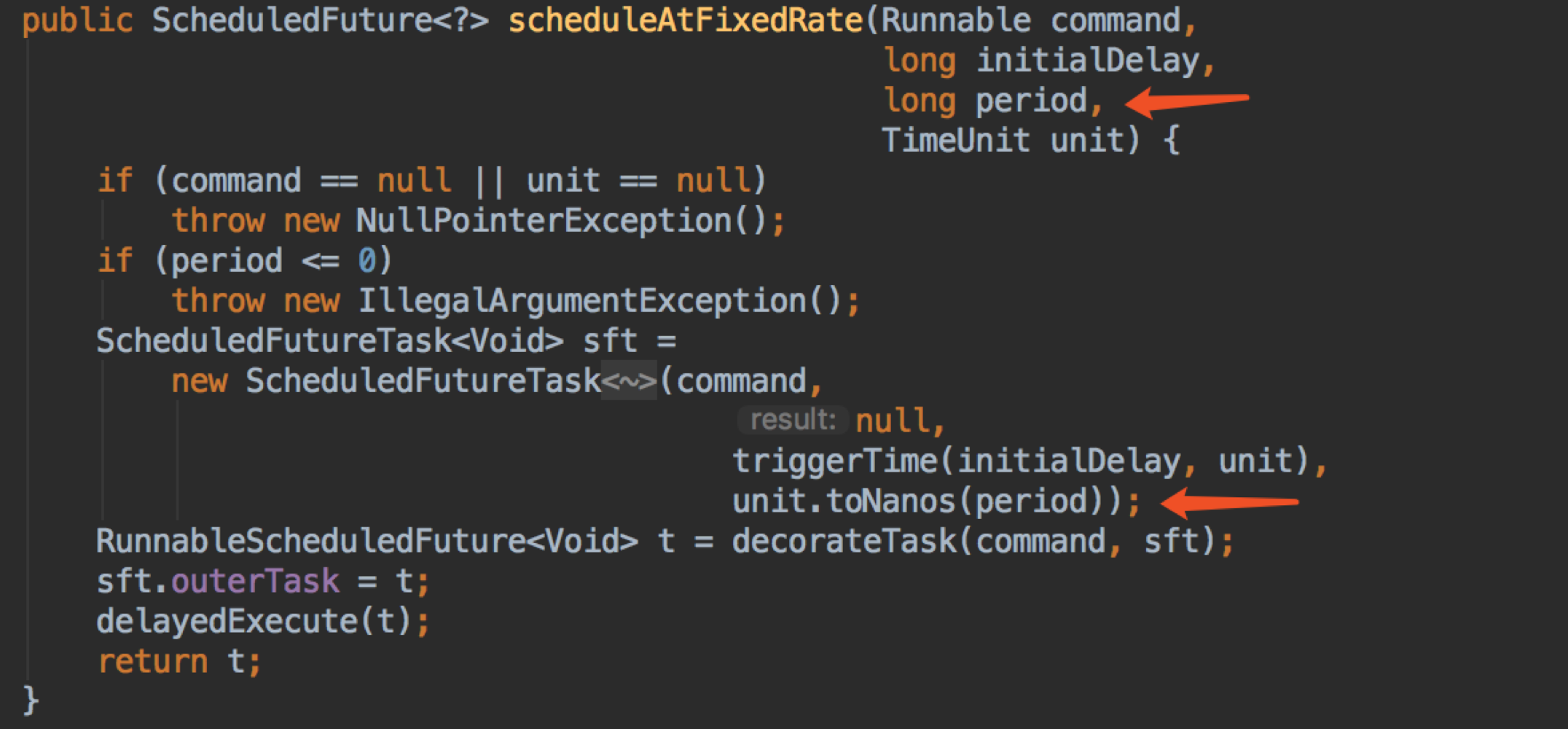
scheduleWithFixedDelay 和 scheduleAtFixedRate 两个方法的区别,相信大家都知道,前者是上一次任务执行完,再延迟 delay 的时间再执行下一次,后者是上一次任务的执行开始时间加上 period 就是下一次任务的执行时间。
我们看到 scheduleWithFixedDelay 和 scheduleAtFixedRate 基本是一样的,就只有当传到 ScheduledFutureTask 的入参时,delay 变成了一个负数,period 还是一样,这一点大家先记住,后面会用到。
继续讲 schedule 方法
decorateTask 方法只是让 ScheduledFutureTask 变成 RunnableScheduledFuture,使得 delayedExecute 更加通用

ScheduledFutureTask 是 ScheduledThreadPoolExecutor 内部定义的任务类,从结构看,简单来说它就是一个 FutureTask + Delayed
我们看看 ScheduledFutureTask 构造方法
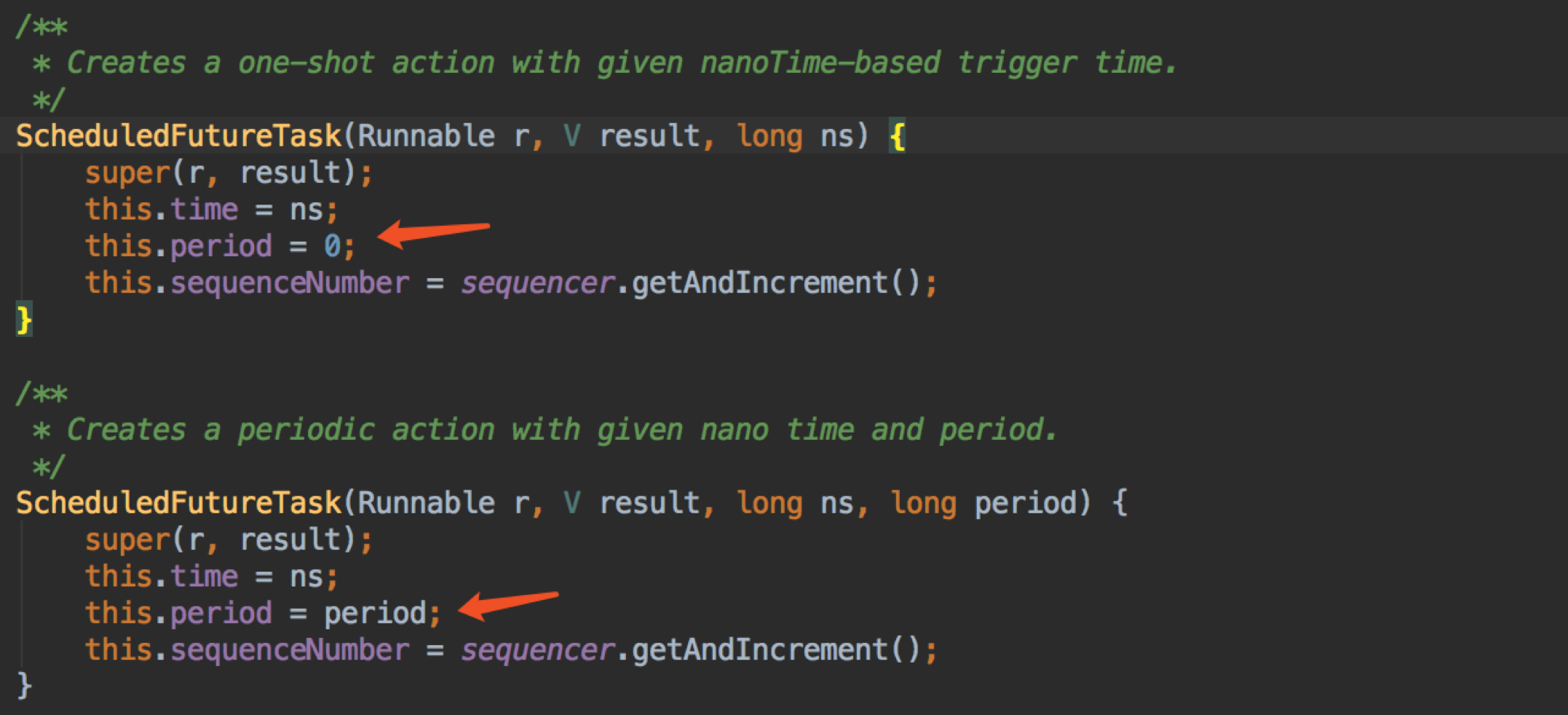
如果是 schedule 则 period 为0,scheduleWithFixedDelay 和 scheduleAtFixedRate 则等于入参,这就是一次性任务和周期性任务的区别
如果是 schedule 则 period 为0,scheduleWithFixedDelay 和 scheduleAtFixedRate 则等于入参,这就是一次性任务和周期性任务的区别
继续看看 delayedExecute
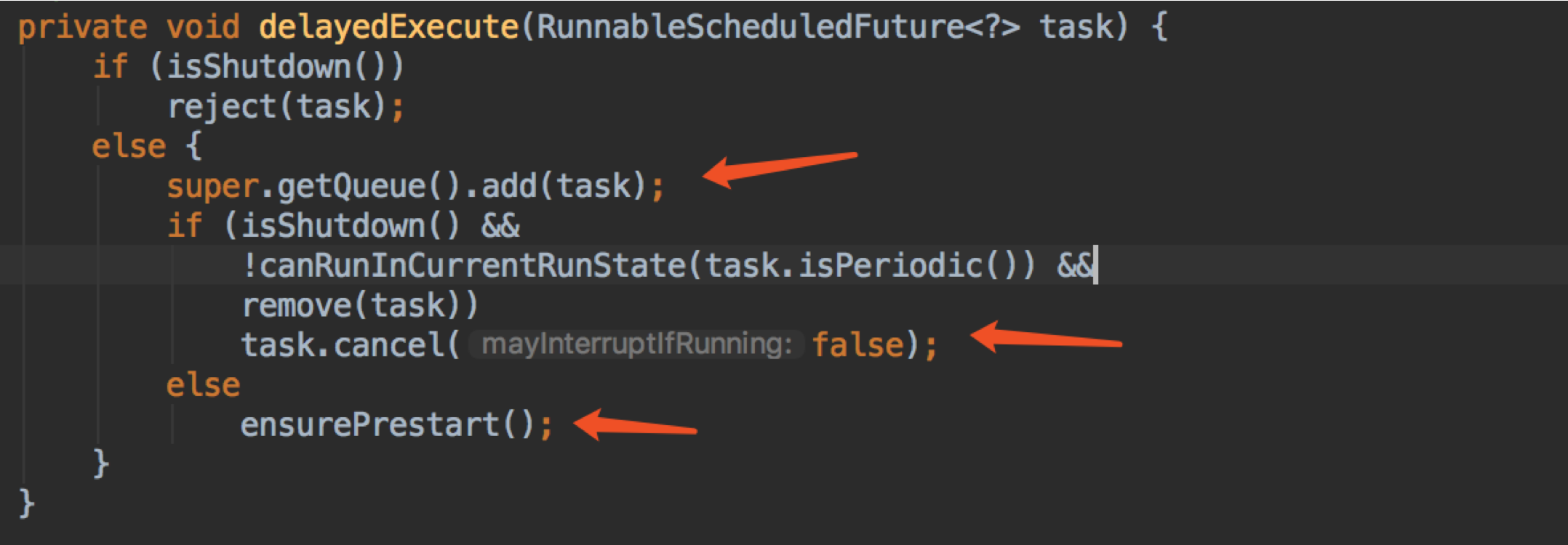
shutdown 就直接 reject;
否则加入到队列,再发现是 shutdown 的话,就 remove 掉,中断 task;
这里为什么直接加入队列?
因为任务的延迟的,一定要确保从延迟队列中取出来运行。
最后调用 ensurePrestart 确保有 worker 在运行;
这里回应上面的, wc < corePoolSize,所以 maximumPoolSize 是没用的。
把任务加到队列了,注意由于队列 DelayedWorkQueue 是类似 DealyQueue,这涉及到 task 的 getDelay 和 compareTo (还记得上面说 ScheduledFutureTask 是一个 Delayed 吗 ),还有这个 queue 是一个二叉堆,涉及 siftUp 和 siftDown 的堆操作,这部分都跟 DealyQueue 比较相关,这里就不展开了。
接下来就是 worker 从队列取出任务,取法跟 ThreadPoolExecutor 一样。
run方法
接下来就是 task 的运行
ScheduledFutureTask 是一个 FutureTask,它覆盖了 run 方法
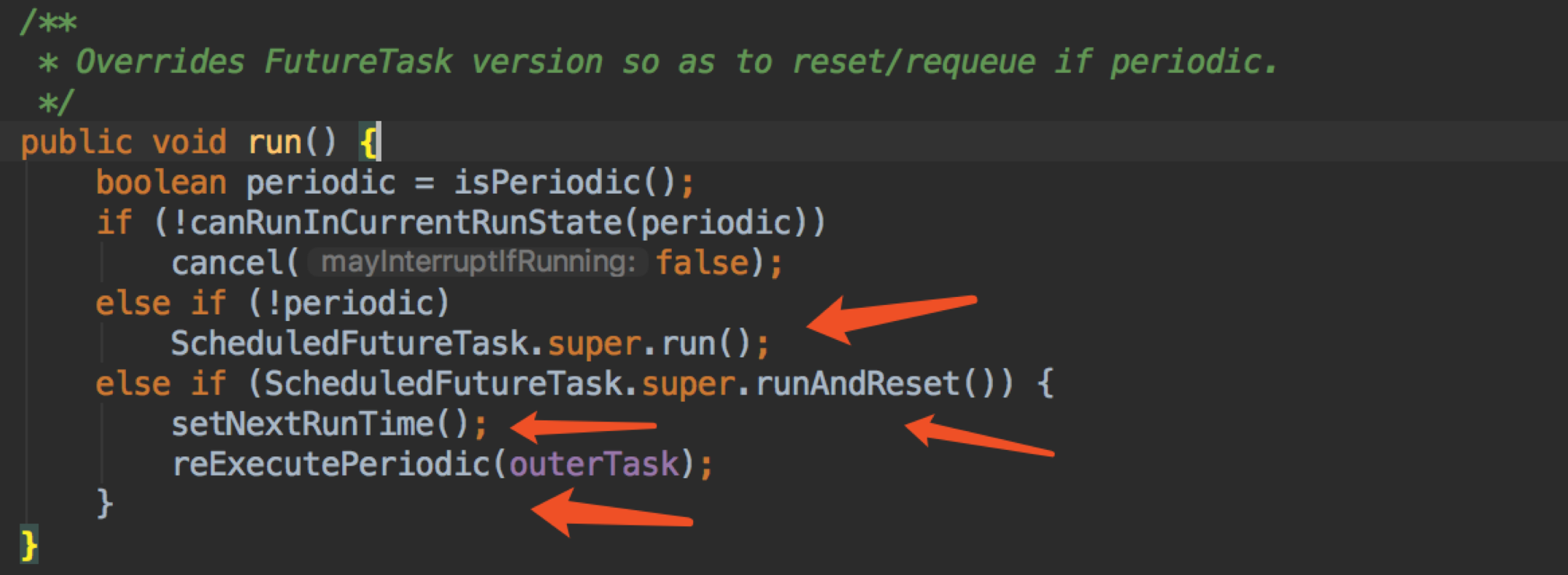
canRunInCurrentRunState,刚刚我们在 delayedExecute 也遇到,它使用来判断线程池是否在运行 RUNNING,如果是 SHUTDOWN,是否允许终止任务;


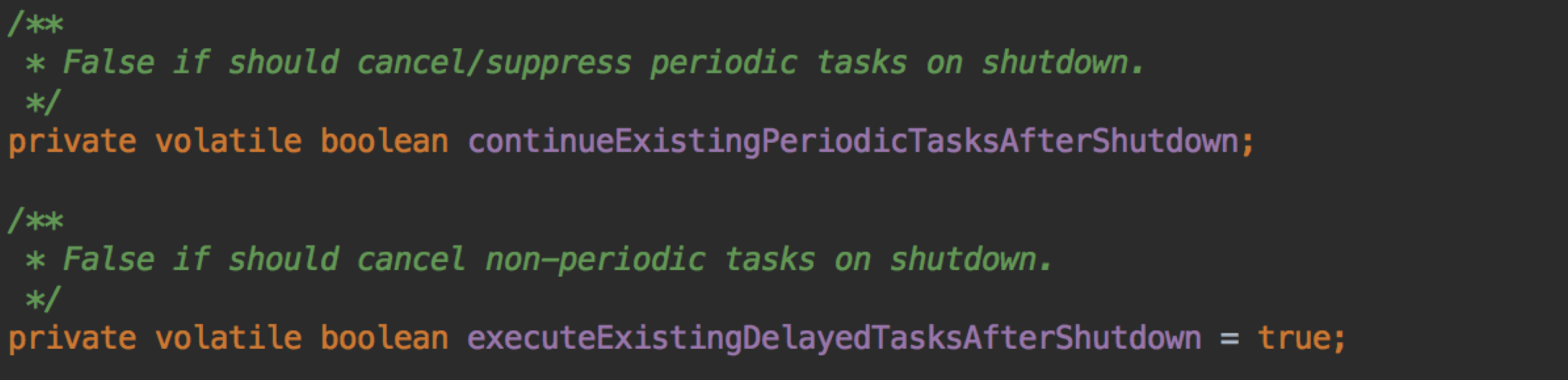
continueExistingPeriodicTasksAfterShutdown 意思是,对于周期性任务,在 SHUTDOWN 下,是否允许继续执行,默认是 false;
executeExistingDelayedTasksAfterShutdown 意思是,对于非周期性任务,在 SHUTDOWN 下,是否允许继续执行,默认是 true;
我们回到重点来,看红箭头。
如果是非周期性任务,那么就调用 FutureTask 的 run 方法;
如果是周期性任务,那么就调用 FutureTask 的 runAndReset 方法(runAndReset 跟 FutureTask 相关,这里不展开了),简单说就是这个 future 执行完之后会重置为 NEW 状态;
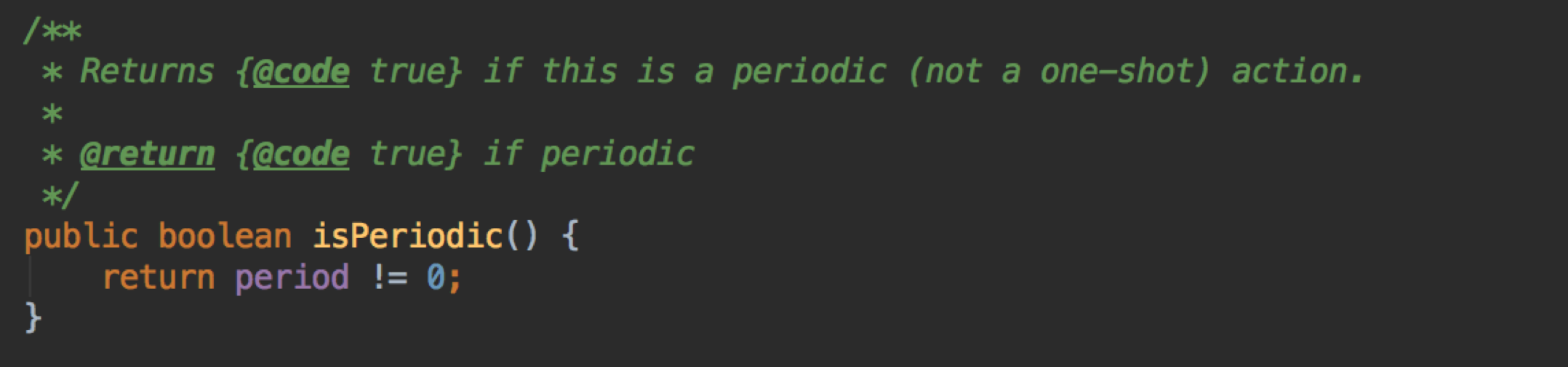
setNextRunTime方法
setNextRunTime 方法,计算任务下一次的执行时间
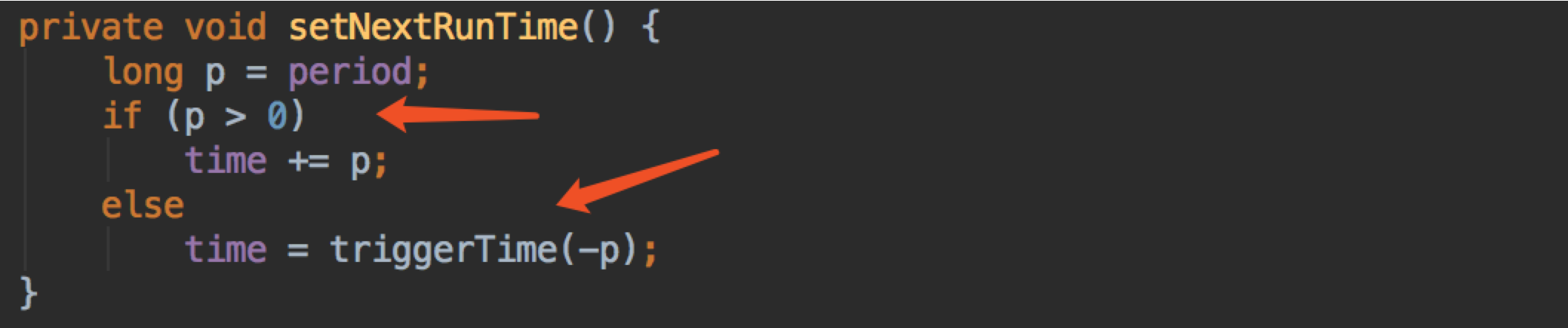
(还记得上面我们说 delay 是负数,period 是原值吗?这里用到了,这两个值都是对应到这里的 period)
如果 p > 0 ,则在原来的时间上 time 直接追加 period,否则在 now() 的基础上追加
triggerTime 获取下次执行任务的时间
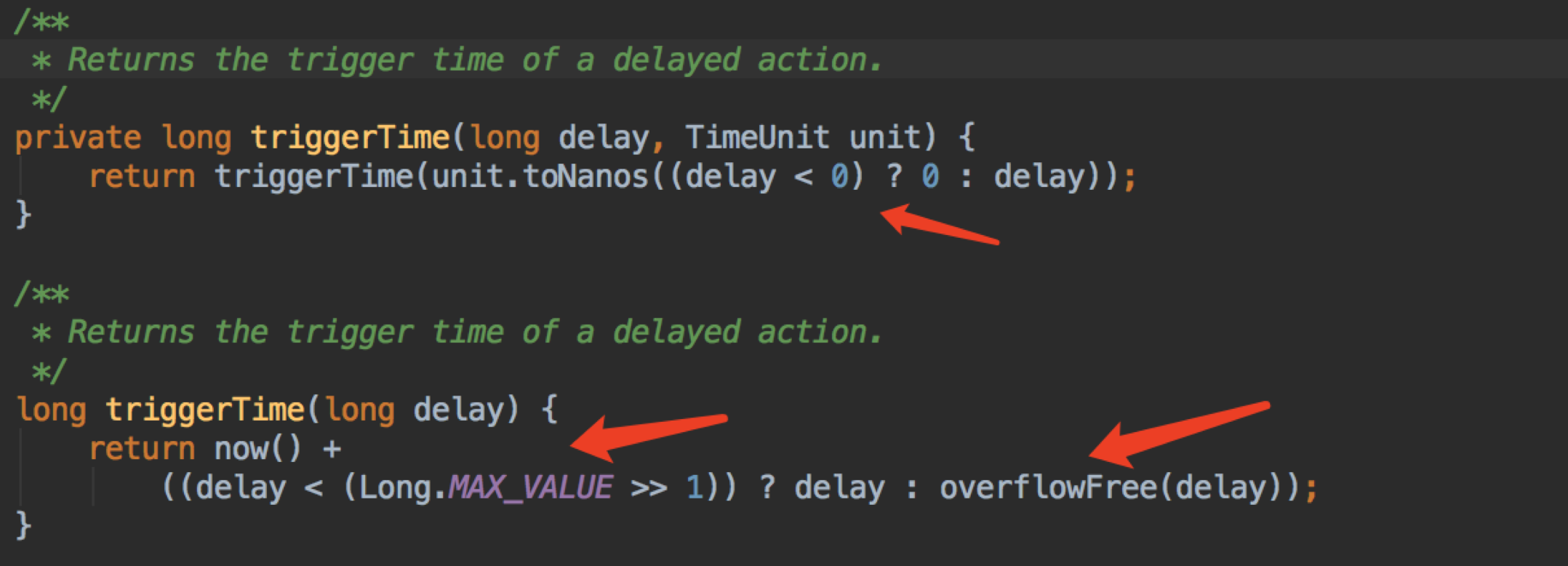
triggerTime防溢出
这里还有一个巧妙的地方,我得说一下
为什么 delay 要跟 Long.MAX_VALUE 右移一位比较?
不急,我们先看看 overflowFree 方法
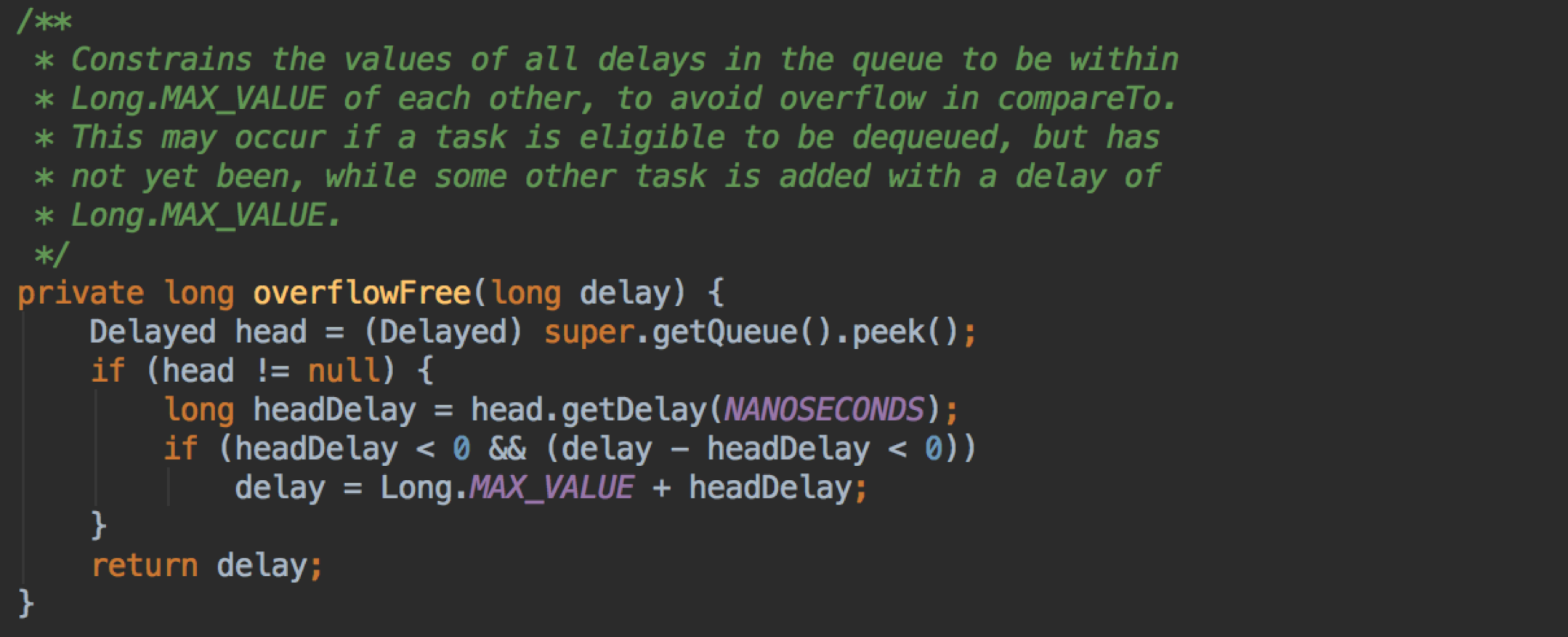
注释已经把大意说清楚了,就是为了防止溢出。因为 head 的 getDealy 有可能是负数(一直没有出队运行),那么当前 task 加入队列时做 compareTo 就有可能溢出(减去一个负数得到一个大于 Long.MAX_VALUE 的数),那么这时比较的结果就不对了。
首先 delay 肯定不为负数,我们分情况看一下:
1、如果 headDealy 为正数(含0),两个正数相减不会溢出,这没问题
2、如果 headDealy 为负数,那么只要 delay - headDealy > Long.MAX_VALUE 就不是我们想要的结果,所以要对 delay 或 headDealy 做一下限制。
我们回到刚刚提出的问题( delay < (Long.MAX_VALUE >> 1) ?)。之所以有这个做法,是因为对 delay 和 headDealy 的值做了一个折中。如果 delay < (Long.MAX_VALUE >> 1) (Long.MAX_VALUE >> 1 就是 Long.MAX_VALUE 的一半),那么就直接用这个 delay 进队;如果大于的话,那就认为它做 compareTo 时极有可能会溢出(这个是人为的认为),那么就取出 headDealy 来试一下,真溢出了,就做调整。这里巧妙的地方在于,它给了 delay 和 headDealy 的值 Long.MAX_VALUE 的一半这么多的预留空间(各占一半),
试想如果把 delay < (Long.MAX_VALUE >> 1) 改为 delay < Long.MAX_VALUE(极端为 delay = Long.MAX_VALUE 的情况),那么 headDealy 只要小于 0 就会溢出。所以只要 headDealy 大于 Long.MIN_VALUE >> 1 就不会溢出。当然,headDealy 是有可能小于 Long.MIN_VALUE >> 1 的,所以为了万一,最后还是会做调整。
reExecutePeriodic方法
我们继续回到重点 reExecutePeriodic 方法
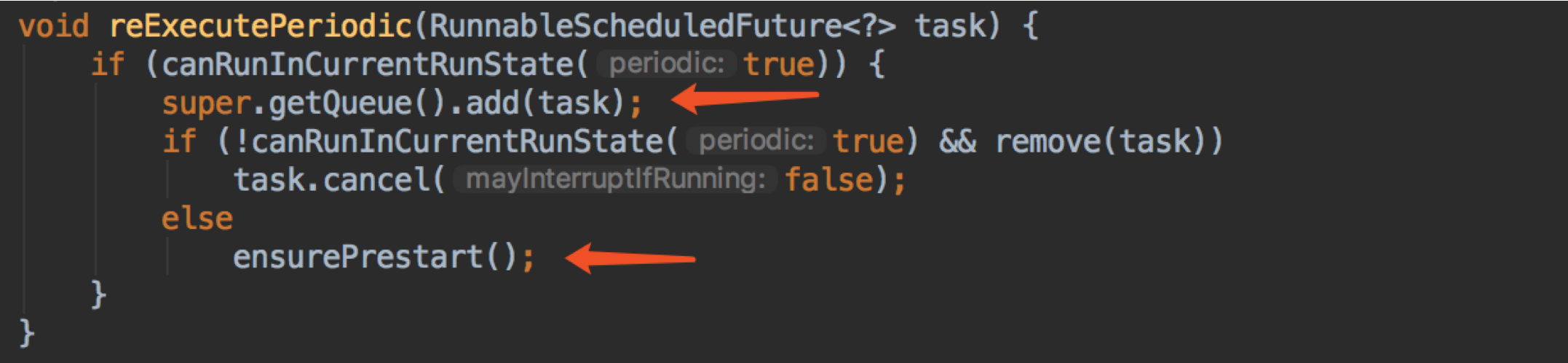
跟之前讲解的代码有点像,相信大家都看的明白了,主要就是把 task 加回到 queue 里。
关闭线程池
ScheduledThreadPoolExecutor 的 shutdown 和 shutdownNow 都是直接调用 ThreadPoolExecutor 的。

至此,ScheduledThreadPoolExecutor 的大概流程和原理讲得7788了。
Why DelayedWorkQueue?
这里补充一下我在看 ScheduledThreadPoolExecutor 源码时心里最大的一个疑问。
为什么不直接用 DealyQueue ,而是另外写了一个 DelayedWorkQueue?
不过还好不用我们自己瞎猜,官方的注释给出了说明
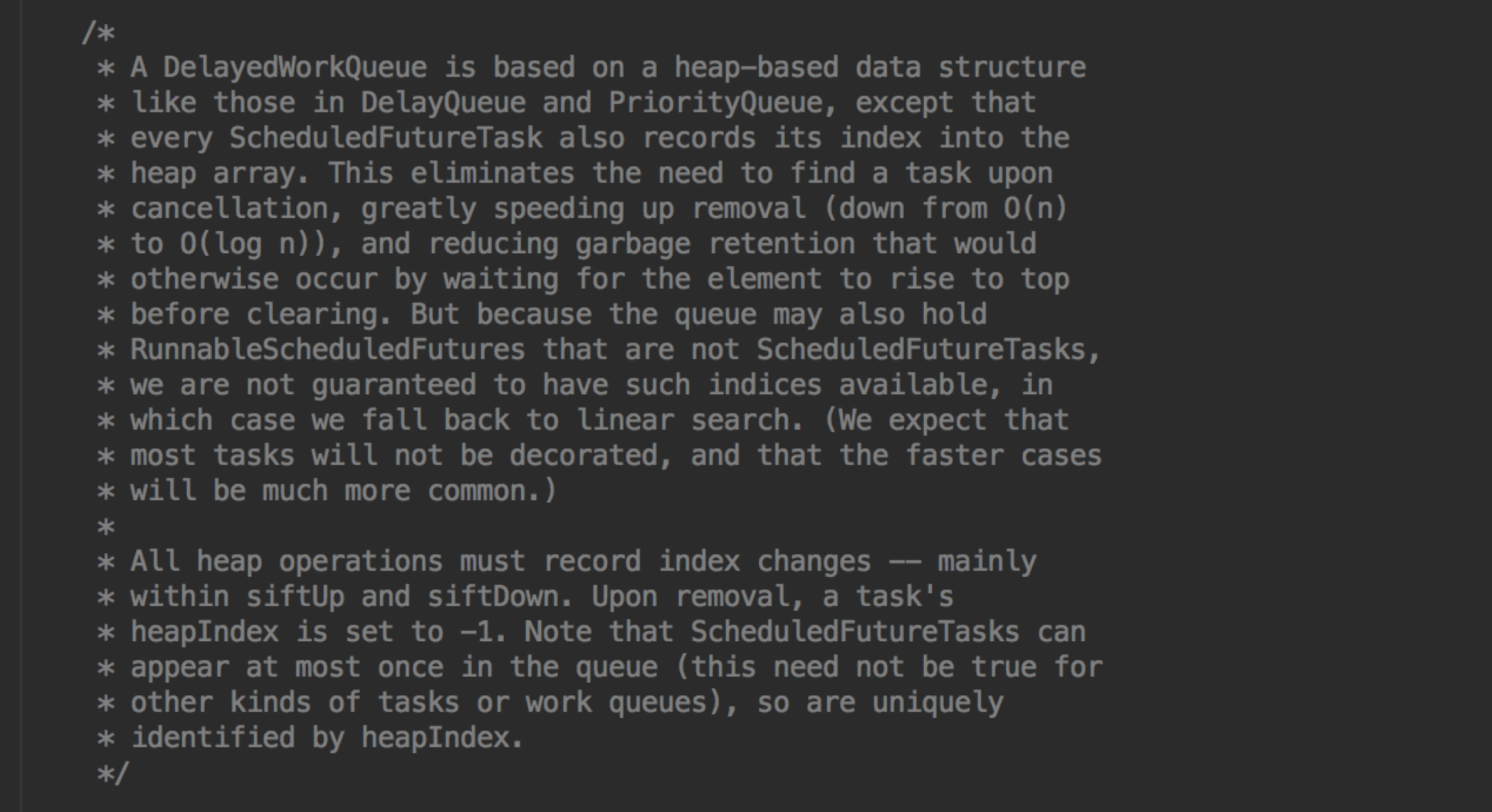
简单来说就是 DelayedWorkQueue 其实跟 DealyQueue 差不多,不过里面的元素 ScheduledFutureTask 会记录在堆的下标,做 remove 的时候时间复杂度从 O(n) 提升到 O(log n)。 所以 DelayedWorkQueue 重写了remove 方法,直接取出元素的 index。
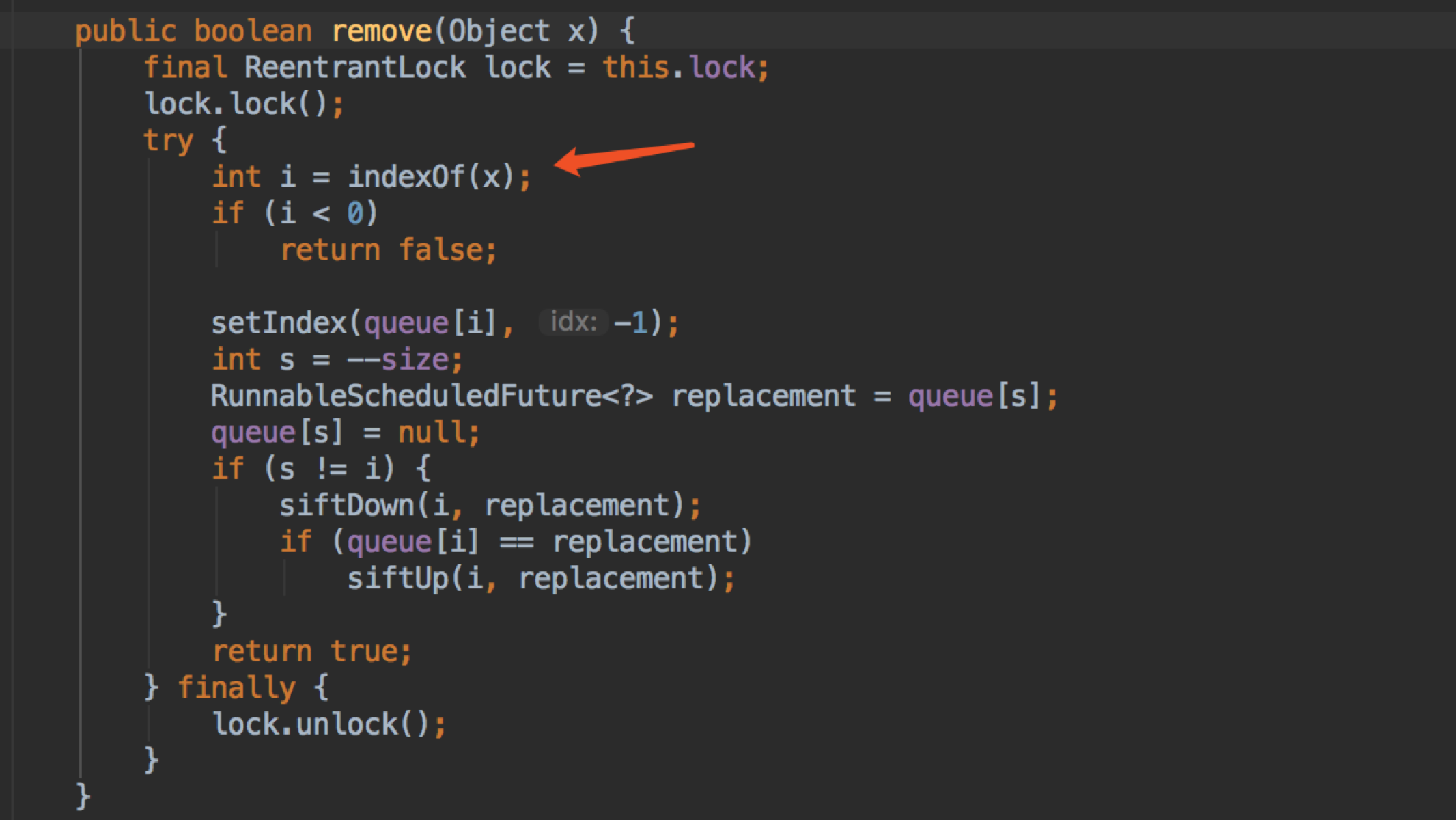
原来 DealyQueue 的做法是遍历数组找出元素的下标(如果元素不是 ScheduledFutureTask 类型也是这样做)+ 堆操作:
O(n) + O(log n) 约等于 O(n) .
DelayedWorkQueue 的操作变为直接取出下标 + 堆操作:
O(1) + O(log n) 约等于 O(log n)
总的时间复杂度从 O(n) -> O(log n)
总结
ScheduledThreadPoolExecutor的实现跟 ThreadPoolExecutor类似,它利用了延迟队列 DealyQueue 对任务进行延迟运行。
参考资料
https://www.jianshu.com/p/2756fd08d0cd
https://www.jianshu.com/p/d96e9f67dba5
Java多线程复习与巩固(七)–任务调度线程池ScheduledThreadPoolExecutor