概要
这是对一次线上正则回溯引起的问题的分析,文章对当时问题进行了简化,从而深入源码分析正则引擎是如何进行回溯以及回溯的时间复杂度。
正则回溯分析
排查过程
zabbix
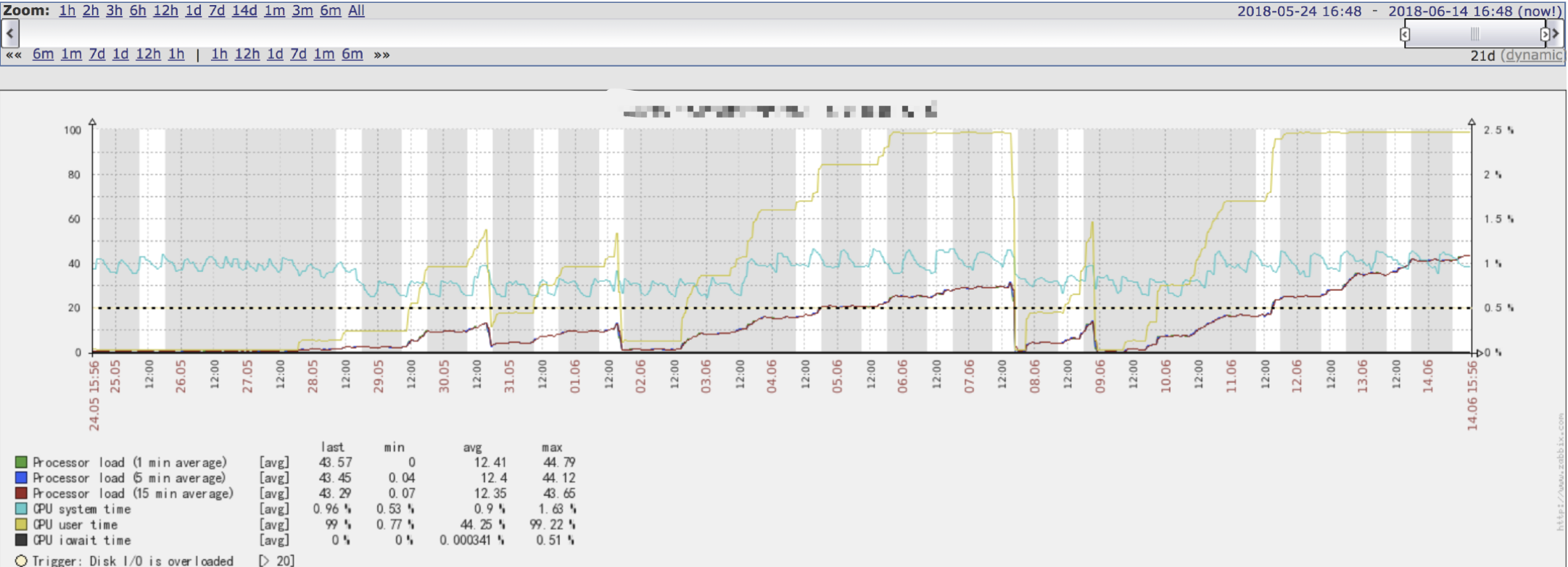
接受到警告之后在 zabbix 看到 cpu 直飚 100%,当堂一惊!(我是CPU,现在慌得一比)。看到是 5.27 后开始飚升,首先怀疑代码问题,认真翻了一下 5.27 前 commit 到 master 的代码,没有发现明显的死循环或者死锁。
于是叫运维帮忙看一下机器状态和 dump 出 jstack。
top & jstack
线上机器 top:
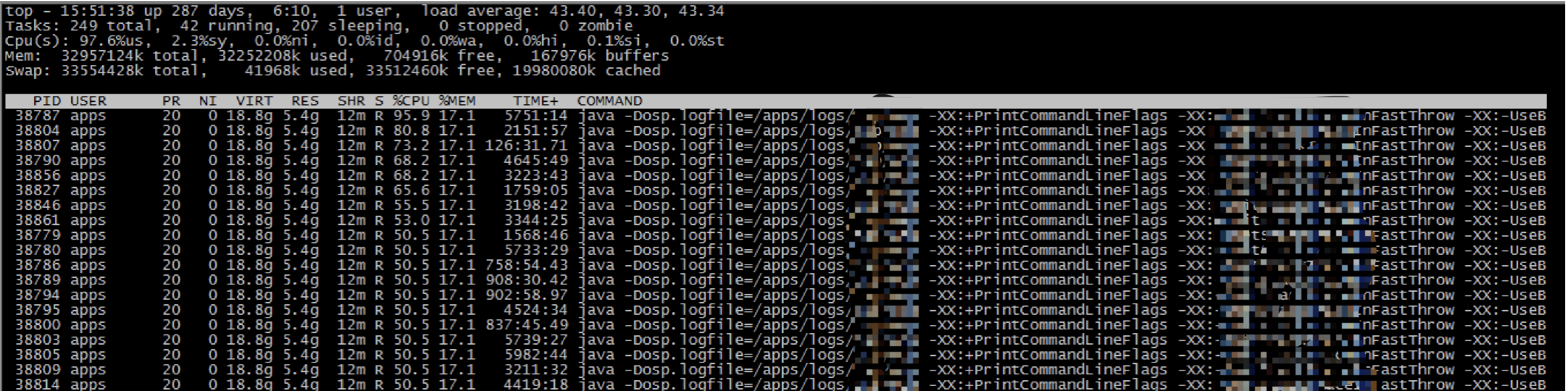
dump:
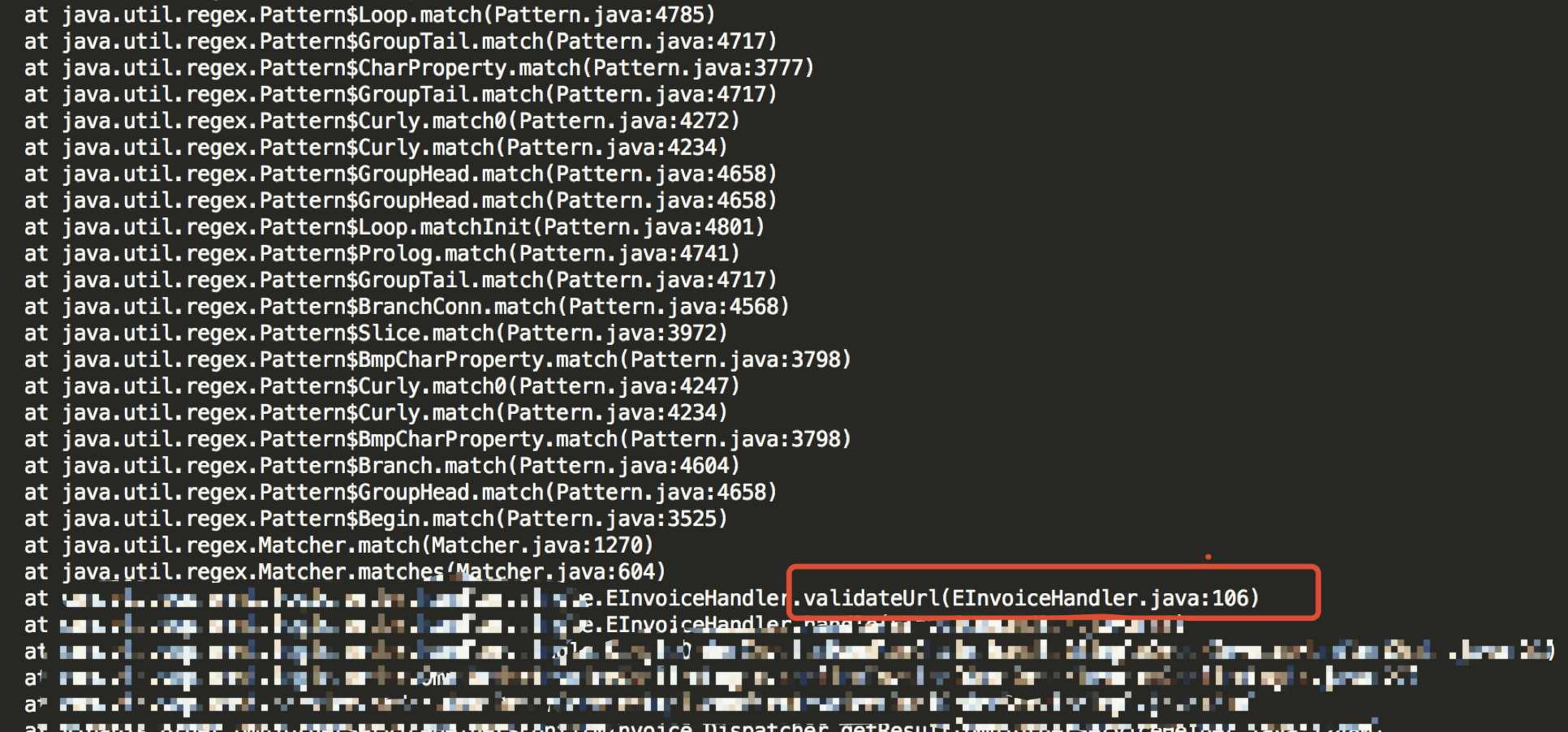
定位问题
可以看出跟正则有关的调用栈很长,于是把问题定位在 validateUrl 方法上。
这是一个用正则去校验一个外部电子发票链接url的方法,其中 url=
1 | http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGmpM5neXWMVrv4ILd-kEn64HcUX4qL4a4qJ4-CEk7Azg.Vjit92m74H5oxkjgdsYazxcUmdJjKscGXhaJw__%5EHGabjgEIe |
其中,正则 pattern =
1 | ^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\/])+$ |
原因分析
阅读前提
阅读下文时,我希望你对正则的基本用法、基本概念,正则的贪婪、懒惰、独占都有一定的理解。
之前,我的一个同事已经对这个做了一定的分析,大家可以先阅读一下 藏在正则表达式里的陷阱
回溯的定义
在网上看了一下大致都说这个是跟正则的回溯有关,那究竟什么是正则的回溯呢?
下面是我在网上找到一个比较好解释,可能看了之后还是懵逼,不怕,接下来会有详细解释
使用 NFA 引擎的模式匹配由正则表达式中的语言元素驱动,而不是由输入字符串中要匹配的字符驱动。 因此,正则表达式引擎将尝试完全匹配可选或可替换的子表达式。 当它前进到子表达式中的下一个语言元素并且匹配不成功时,正则表达式引擎可放弃其成功匹配的一部分,并返回以前保存的与将正则表达式作为一个整体与输入字符串匹配有关的状态。 返回到以前保存状态以查找匹配的这一过程称为回溯。
简化还原分析
由于原来的url和pattern太长有点复杂,不好做分析,所以我进行了简化,方便做调试和分析。根据正则的贪婪和回溯特性,我做了如下的简化。(如果你对正则有一定的理解,相信你也会对原来url和pattern做到如下的简化)
url=
1 | aaaaaaaaaaaa_ (只是想表示有 n 个 a) |
pattern=
1 | (a+)+ |
以下的分析都是基于上面的ur和pattern。
(基于JDK8)通过调试代码,我发现匹配字符的类最后是在 CharProperty 的 match 方法;其中通过 Character.codePointAt(seq, i) 这个方法获取需要匹配的字符,其实这个方法终于还是调用 CharSequence 的 charAt 这个方法
1 | /** |
于是我在 stackoverflow 找到一个继承 CharSequence 的类来做一些辅助 InterruptableCharSequence ,主要是打印当前匹配的字符和匹配次数,还有后面要做的中断。
1 | public class InterruptableCharSequence implements CharSequence{ |
推出时间复杂度
通过调试代码和根据打印信息,可以得出正则回溯的匹配过程:
假设 url=a_,pattern=(a+)+
(1) a 匹配,继续
(2) _ 不匹配
以上两步是第一个 + 的匹配过程
(3) 尝试匹配 _ 看看是不是可以结束
以上这一步是第二个 + 的匹配过程
(4) 没有回溯,结束(没有回溯是没有发生贪婪,发生贪婪的条件是从第一个字符匹配成功后,下一个字符又匹配成功)
所以这时一共匹配了 3 步,匹配顺序为:1
a _ _
假设 url=aa_,pattern=(a+)+
(1) ~ (3) 匹配到了 aa_
(4) 尝试匹配 _ 看看是不是可以结束
(5) 发生回溯,后退一步,递归 a_ 的匹配过程
(n) 最终还是匹配不成功,结束
所以这时一共匹配了 7 步,匹配顺序为:1
a a _ _ a _ _
假设 url=aaa_,pattern=(a+)+
(1) ~ (4) 匹配到了 aaa_
(5) 尝试匹配 _ 看看是不是可以结束
(6) 发生回溯,后退一步,递归 a_ 的匹配过程
(…) 上一步最终还是匹配不成功的,于是又后退一步,递归 aa_ 的匹配过程
(n-1) 直到回退到第一个 a,回溯结束,已经遍历了所有的情况
(n) 最终还是匹配不成功,结束
所以一共匹配了 15 步,匹配顺序为:1
a a a _ _ a _ _ a a _ _ a _ _
根据上面我们可以推断出时间复杂度:
1 | f(1) = 1 |
回溯源码分析
现在我们来回头看看正则回溯的相关代码,主要是在 Curly 的 match0 方法
1 | // Greedy match. |
从代码和注释得知,开始匹配成功后,就会进入贪婪模式,直到匹配不成功,然后开始发生回溯,用 backLimit 这个变量记录最开始匹配成功的下标,即允许回溯最后的地方。
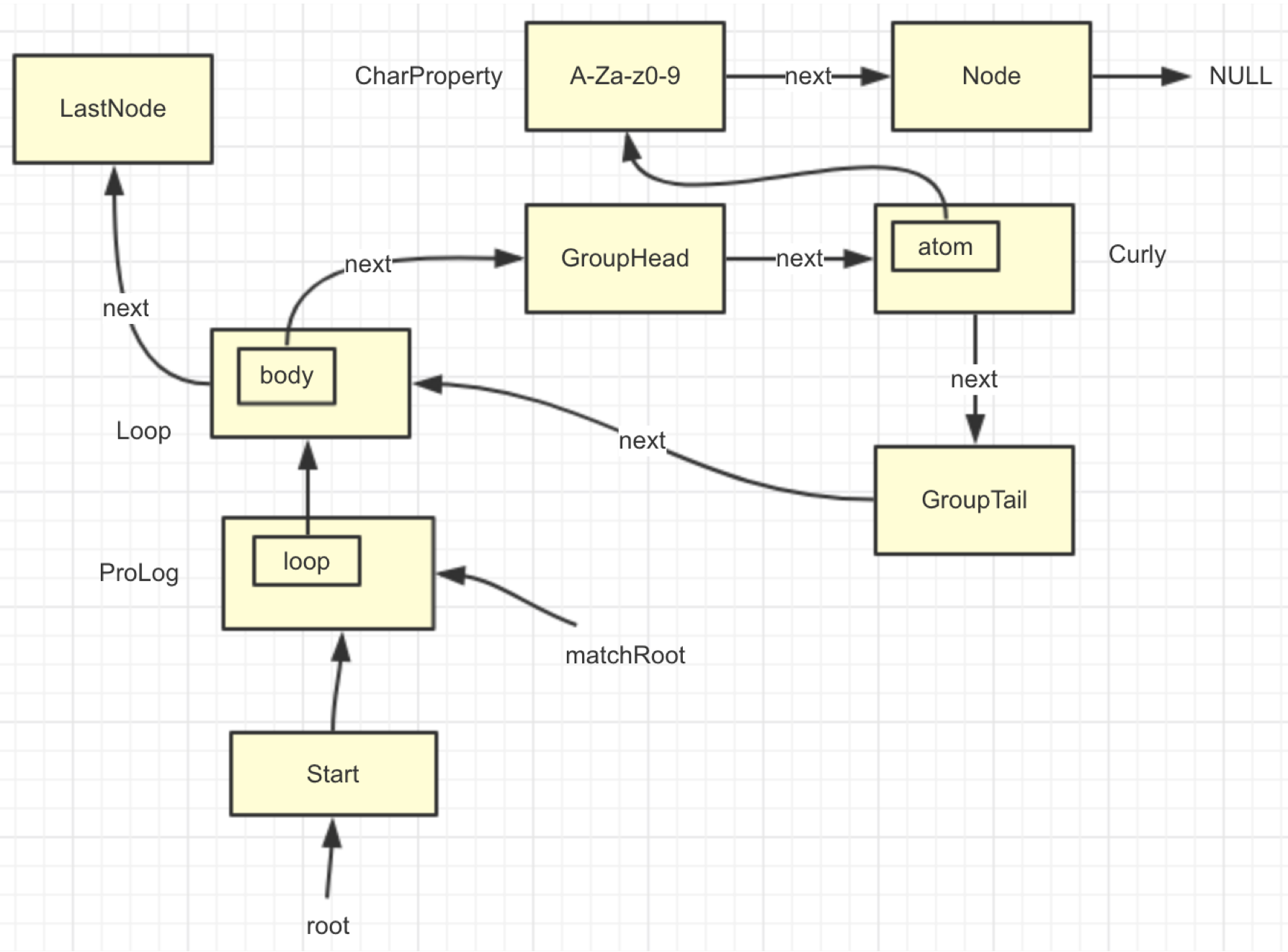
开始发生回溯的地方,即第33行的 next.match 方法,这个 next 指的是下一个节点(因为 java 实现 NFA 用了类似图(graph)的数据结构,匹配的地方,group开始和结束的地方等等都抽象成一个个 Node),由于第二个 + 的原因,构成了一个有环的图,于是发生递归。
以下是我调试时根据 Node 的关系,画出来的图:
线上问题的url分析&解决
现在回过头来看看导致线上问题的原因:
先把正则简化一下, pattern=
1 | ^(http://)(([A-Za-z0-9-~]+).)+$ |
加点打印信息,可以看出从第24行开始发生回溯 :
1 | 8 ww.fapiao.com/dzfp-web/pdf/download?request=6e7JGmpM5neXWMVrv4ILd-kEn64HcUX4qL4a4qJ4-CEk7Azg.Vjit92m74H5oxkjgdsYazxcUmdJjKscGXhaJw__%5EHGabjgEIe |
于是,可选的解决方案有:
使用可选限定符或替换构造的回溯
1
2
3(http://)(([\\S]+).)
(http://)(([\\S]+?).)
(http://)(([A-Za-z0-9-~_%]+?).)非回溯子表达式
1
^(http://)(?>([A-Za-z0-9-~]+).)+$
如何避免
综上,我个人总结以下四点来规避上面的正则回溯问题。
充分考虑输入
除了考虑正确的输入外,更重要的是考虑不匹配的输入!发生回溯都是因为不匹配导致的,正则会不停的尝试匹配,直到所有可能的情况。
推荐一个探测工具:
https://regex101.com/
控制回溯
发生回溯是因为正则用到了量词(quantifier)和 替换(alternation)(因为这两者为正则的匹配提供了可能性)。
可以加上使用断言(assertions)或 独占模式(possessive),这样可以减少回溯的次数或者避免回溯,但是加上了断言和独占就要考虑对原来的匹配有没有产生影响,匹配结果是否还是一致。
量词:?, *, +, {n,m}
替换:[x|y] 类似这种
断言:(?=exp), (?!exp) 类似这种
独占模式:在量词后面再加上一个 +,表示匹配到此为止,不会回吐字符,即不会回溯。
使用超时机制
但是本人认为回溯是不能避免的,那么就可以使用超时机制,用中断线程的方法来强制结束线程,不要让它在死跑,耗尽CPU资源
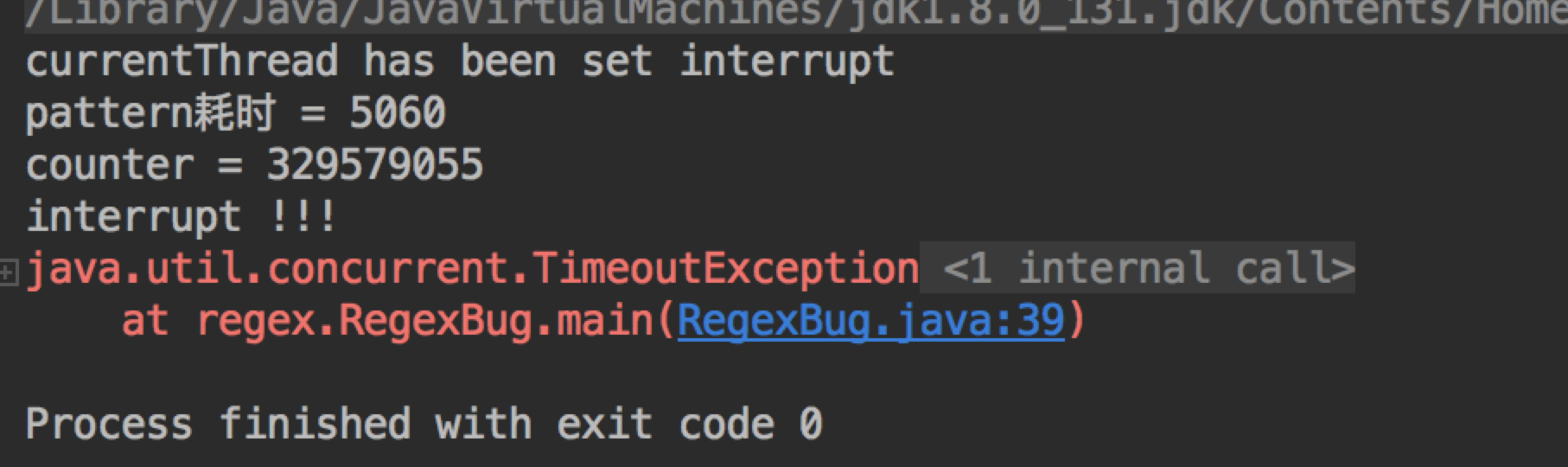
以下是本人写的一个小测试:
1 | public class RegexBug { |
日志:
使用现成工具校验
与其自己写正则担心写出bug,不如用现成的工具。
apache common-validator 了解一下
参考资料
https://www.cnblogs.com/study-everyday/p/7426862.html
http://wwaw.cnblogs.com/chanshuyi/archive/2018/06/19/9197164.html7164.html